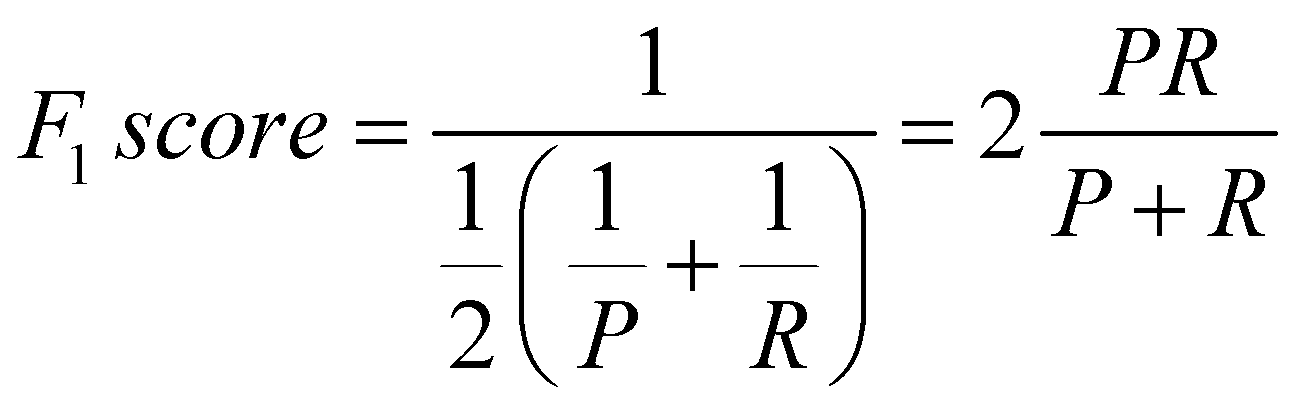于偏斜数据集适用的一种误差指标。
# 序
在二元分类偏斜数据集中,正负例子占比远离五五开,可能正例较负例少得多。这时分类错误占比指标不能很好地衡量模型的表现,因为在该指标下 y=0 也能表现地很好。
# Precision/Recall
如下图所示,将模型输出结果分为四类: 真阳性 True positive 、假阳性 False positive 、假阴性 False negative 、真阴性 True negative 。
- TP: 真阳性指预测为正实际上也为正。
- FP: 假阳性指预测为正但实际上为负。
- FN: 假阴性指预测为负但实际上为正。
- TN: 真阴性指预测为负实际上也为负。
准确率 Precision 指真阳性对所有预测为阳性的占比; 召回率 Recall 指真阳性对所有实际上为阳性的占比。

准确率或召回率很高时说明算法在偏斜数据集上的表现较好,然而在特定情况中这两者需要权衡。
# 权衡准确率与召回率
如在LR中,通过设定阈值 Threshold 来控制函数的输出。若想极高得确保真阳的准确性,那么可以提升阈值。这样准确率会提高,而召回率会下降,因为预测为阳性的例子变少了; 若想尽可能不放过漏网之鱼,那么可以降低阈值。这样准确率会下降,而召回率会提高。
这是一个权衡的过程,手动选择阈值并权衡准确率与召回率。若不想手动权衡,可以引入 F1 score 帮助用户判断模型的好坏。

调和平均数 F1 score 将准确率与召回率合并为一个分数,得分最高的模型表现最好。