R严格区分大小写
# 参考

An Introduction to R
官方团队出版的关于R的小册子。
Link
https://cran.r-project.org/doc/contrib/Lam-IntroductionToR_LHL.pdf
R in Action
前七章为基本内容。各方推荐(?
Link
https://livebook.manning.com/book/r-in-action-third-edition


R for Data Science
实战中有用,但不基础,需要先看前两本。
Link
https://r4ds.had.co.nz/
Quick-R:https://www.statmethods.net/index.html
# 安装Rtools
在安装Packages之前,需要安装Rtools。
https://cran.r-project.org/bin/windows/Rtools/
# 安装Packages
1.使用命令行安装Packages
install.packages("MASS")2.右下角点击Packages搜索想要安装的包并安装
3.头部导航条Tools里有个Install Packages,搜索想要安装的包并安装
一些经典的包:
dplyr:数据预处理
ggplot2:画图经典包
reshape:调整数据结构
rmarkdown:快速生成文档,可导出pdf, ppt, word
data.table:处理较大数据集
寻找想要的包:
可以去RDocumentation找想要的包去实现某个功能。

# 包的使用
library(MASS) //调用包,加了引号没办法自动补全包的名词。所以这里不加引号比较好。
library(help="MASS") // 获取关于包的信息,使用方式、作者等
help(package="MASS") // 和上面的一样
?boxcox //获取boxcox这个方法的帮助文档。这个查看帮助的方法需要先加载包。
??boxcox //获取boxcox这个方法的帮助文档。这个查看帮助的方法不需要先加载包。
help("boxcox") //获取boxcox这个方法的帮助文档,不加引号自动补全方法名称和双引号。这个查看帮助的方法需要先加载包。
boxcox() //调用一个函数
detach("package:MASS") //移除加载的MASS包
remove.packages("MASS") //从硬盘删除MASS包在调用某个函数之前,得先用library(‘package_name’)调用这个包。
# R中的数据类型
- 数值型,数值可以直接进行加减乘除运算。
- 字符串型,可以进行连接、转换和提取等。
- 逻辑性,真或假。
- 日期型。
向量:
是构成其他数据结构的基础。与数学上的向量不同,这里更类似于集合的概念,由一个或多个元素组成。
c(1,2,3,4)
c("好","呀","好","呀")
c(1,"好")# 数据读入
手动键入数据:
将每一列数据输入到对应的向量,然后把向量都整合到一个data.frame中。
使用 edit() 函数可视化键入数据:
kidData <- data.frame(kidName = character(), kidGender = character(), kidBirthdate = character(), kidAge = numeric())
kidData <- edit(kidData) //弹出数据编辑器,这是个windows form,就可以手动键入数据了
fix(kidData) //弹出数据编辑器,但可以直接保存,不用在前面加 kidData <-txt格式数据:
1.read.table()
read.table("C:\\Users\\me\\Desktop\\table1.txt", header=T, sep="/", skip = 5)
header=T的意思是以第一行为表头,/是每个数据的分隔符。\在R中也是转义字符。skip = 5 表示跳过前面5行,从第6行开始读取数据。还可以设置nrows参数控制读取到哪里,和skip参数组合,可以读取文本里的任何部分
还有一个参数是na.strings,这是告诉R文本里的什么是缺失值,然后R会自动把这个东西替换成NA
更多参数可以查看read.table的帮助文档
如果不想让第一行被当作表头,则把header=T这个参数删掉就行了。
2.readLines()
readLines("C:\\Users\\me\\Desktop\\table1.txt")
一行一行读进去数据。比如一些诗歌之类的。还可以设置参数n来规定读入的行数
3.read.fwf()
read.fwf("fwf.txt", widths = c(2,2,3))
读取固定宽度的文件。比如有一系列的"aaa" "bbb" "cccccccc"数据从存储在txt中,则用该函数读出来是 aa bb ccc
head(x, n=10) //显示数据的前十行
tail(x, n=10) //显示数据的后10行EXCEL的文件:
安装xlsx包,需要先安装Java。这是依赖。
1.read.xlsx2() //xlsx1也行,但大数据下速度较慢
read.xlsx2("C:\\Users\\lenovo\\Desktop\\1.xlsx", 1, header=T)
1是指Sheet1,表头还是那个意思,没有表头就把header=T删了。
2.read.csv()
read.csv2("C:\\Users\\lenovo\\Desktop\\1.csv",header=T)
这里加1报错,不知道为什么非文本文件:
install.packages("XML") //比如读取HTML中的表格,则需要XML包
?readHTMLTable //查看一下帮助
readHTMLTable("xxxx.html", which = 2) //读取某网页的第二个table标签的内容
读取剪切板的数据
x <- read.table("clipboard", header = T, sep = ",") //如果目录下还存在同名文件,则可以加file参数 read.table(file = )
readClipboard() //直接读取剪切板的信息
读取压缩的文件
read.table(gzfile("ada.txt.gz"))读取其他软件数据:
help(package = "foreign") //使用自带的foreign包,来读取SAS、SPSS、ARFF、DBF、STATA BINARY、EPI INFO DATA等数据读取不规则数据:
?scan
使用scan()函数来读取不规则存储的数据,比如有六列数据,很多行,格式是这样的:aaa 1 2 bbbb 3 5,有很多行
scan("a12b34.txt", what = list(character(), numeric(), numeric()))
就可以按照字符串、数字、数字来读取
先读aaa然后bbb,然后aaa,然后bbb...,这是第一列
先读1然后3,然后1,然后3...这是第二列
先读3然后5,然后1,然后5...这是第三列
输出
[[1]]
[1] "aaa" "bbbb" "aaa" "bbbb" "aaa" "bbbb" "aaa" "bbbb" "aaa" "bbbb" "aaa" "bbbb" "aaa" "bbbb"
[[2]]
[1] 1 3 1 3 1 3 1 3 1 3 1 3 1 3
[[3]]
[1] 2 5 2 5 2 5 2 5 2 5 2 5 2 5读取R文件格式数据:
readRDS() //读取RDS格式的文件
load() //读取Rdata文件,但有个问题,如果现在的工作空间有一些变量,那么新的load会覆盖掉重名的变量# R中的数据
向量:
用 c() 来创建向量。向量可以装一列数据(是列向量)。向量可以装字符,也可以装数字。用 c() 来创建向量。向量可以装一列数据(是列向量)。向量可以装字符,也可以装数字,还可以装T\F布尔值。
一个向量只能存同一个类型的数据。
c(1,2,3,4)
c("好","呀","好","呀")
c(1,"好") //这里的1也会被转为字符串
c(T,T,F)
c(1:100) //生成从1到100的等差数列
seq(from=1,to=20,by=5) //生成等差值为2的从1到20的等差数列。
seq(1,100,length.out=10) //起始值为1,终止值为100,生成10个值,并且是等差数列。
rep(c(1,2),5) //重复生成5次包含1和2的向量。1212121212
rep(c(1,2),each=5) //重复生成5次包含1和2的向量。1111122222
rep(c(1,2),each=5,times=2) //重复两次生成5次包含1和2的向量。11111222221111122222访问向量里的数据:
x <- rep(c(1,2,3,4,5),c(1,2,3,4,5)) //对12345的这个向量进行对应的循环。122333444455555
x[1] //输出x向量中第一个值
x[-10] //输出所有值,不含第19个
x[c(1:5)] //输出第1个到第5个值
x[c(1,1,4,6)] //输出对应位置的值
x[c(T,F)] //按照顺序来输出,第一个为T输出,第二个为F不输出,第三个为T输出...
x[c(T)] //输出所有值
x[x>1 & x<4] //输出x>1同时x<4的值
z <- c("one","two","three","four","five")
"one" %in% z //得到TRUE
z %in% c("one","two") //得到TRUE TRUE FALSE FALSE FALSE
k <- z %in% c("one","two") //k的值为TRUE TRUE FALSE FALSE FALSE
z[k] //输出"one" "two"
names(z) <- c("a1","a2","a3","a4","a5") //给对应的值赋一个名字。如果只输一个,就对第一个赋名字
z["a3"] //调用这个赋予的名字可以得到数据。
修改向量:
b <- 1:3 //b就为1 2 3
b[c(4,5,6)] <- c(4,5,6) //给b向量的第4 5 6个位置分别赋值4 5 6,于是b向量就是1 2 3 4 5 6了
b[20] <- 4 //b向量的第20个位置赋予4,但是中间有很多位置没有值,那就是NA
append(x = b,values = 6,after = 5) //把6插到b向量的第五个位置之后。这时b向量是没有变的。除非在前面加 b <- append...
b <- b[-c(1,2)] //删除b向量的第1 2项
b[2] <- 10 //给b向量第二项重新赋值
rm(b) // 删除向量b
向量运算:
x <- 1:10
x <- x+1 //每一个元素都会加1.得到 2 3 4...
x+y //向量的加法运算
x^y //向量的乘幂运算,和x**y等价
x%%y //求余运算
x%/%y //整除运算
运算中,其中长的向量的个数必须是短的向量的整数倍
x<5 //得到TRUE TRUE TRUE TRUE FALSE FALSE....可以用来比两个向量
c(1,2,3) %in% c(1,2,2,4,5,6) //包含符。得到TRUE TRUE FALSE,就是看左边的向量在右边是否存在
x==y //判断x向量是否等于y向量。注意是两个等号矩阵:
用 matrix() 来创建矩阵。矩阵只装数字。
matrix(c(1,2,3,4,5,6,7,8,9),nrow = 3,ncol = 3,byrow = T)
c()创建了纯数字的向量,nrow表示有几行,ncol表示有几列。byrow=T/F,表示是否按照行来排列。
matrix(1:20,4,5,T) //简写,4行5列,按照行来排
matrix1<-matrix(c(1,2,3,4,5,6,7,8,9),nrow = 3,ncol = 3,byrow = T)
matrix1
给这个矩阵取个名字,matrix1。之后输入matrix1就可以调用这个矩阵了。
x <- 1:20
rnames <- c("R1","R2","R3","R4")
cnames <- c("C1","C2","C3","C4","C5")
dim(x) <- c(4,5) //把x向量的维度改成4行5列的数组
dimnames(x) <- list(rnames,cnames) //给行和列赋予名字
x<-1:6
dim(x) <- c(2,3)
dimnames(x) <- list(c("R1","R2"),c("C1","C2","C3"))
输出
C1 C2 C3
R1 1 3 5
R2 2 4 6
矩阵的另一种创建方式:
dimName1 <- c("A1","A2")
dimName2 <- c("B1","B2","B3")
dimName3 <- c("C1","C2","C3","C4")
z <- array(1:24, c(2,3,4), dimnames = list(dimName1, dimName2, dimName3))
这里的c(2,3,4)代表维度访问矩阵里的数据:
m <- matrix(1:20,4,5,T)
m[2,3] //输出第2行第3列的元素,8
m[1,c(2,3,4)] //输出第1行,第2 3 4个元素
m[2,] //输出第2行的元素
m[,2] //输出第2列的元素
m[-1,2] //去掉第1行,输出第2列
m["A1","B2"] //如果每行每列都有别名,可以通过名字找对应的元素矩阵的运算:
矩阵与矩阵的运算需要行列数一致
colSums(m) //求每一列的和的值
rowSums(m) //求每一行和的值
colMeans(m) rowMeans(m) //求每一列、行的平均值
m*t //m和t为行列数相同的两个矩阵,这是求内积
m %*% t //求外积
diag(matrix(1:9,3,3,T)) //求n阶对角矩阵的对角线
t(m) //矩阵转置数据框:
用 data.frame() 来创建数据框。既可以装数字又可以装字符,还有清晰的结构。
它像是一种表格式的数据结构,目的在于模拟数据集。它会构成一个矩形数组,行表示观测,列表示变量。它实际上是一个列表,列表中的元素是向量,这些向量构成数据框的列,每一列必须具有相同长度,而且列必须命名。
dogNumber<-c(1,2,3)
dogName<-c("gougou","zhuzhu","niaoniao")
myDogs<-data.frame(dogName,dogNumber)
myDogs
Output:
dogName dogNumber
1 gougou 1
2 zhuzhu 2
3 niaoniao 3
myDogs[1,2] 查看第一行第二列的内容
myDogs[1,] 查看第一行的内容
myDogs[,2] 查看第二列的内容
myDogs$dogName 查看dogName这一列的内容访问数据框里的数据:
state里有很多关于美国的数据,如果要分析美国的某些数据刚好要用到这些数据,可以把它们存在一个数据框内,再进行分析
frame1 <- data.frame(state.name, state.abb, state.region, state.x77)
frame1[1] //输出数据框的第一列,它也会输出行名和列名,因为输出的还是数据框
frame1[c(1,2)] //输出数据框的第一列和第二列,输出的是数据框
frame1[,"state.name"] //输出state.name这一列,输出的是值,而不是数据框
frame1[,1] //输出第一列的值,而不是数据框
frame1[1,] //输出第一行,是数据框
frame1[,-1] //输出所有数据,不包括第一列的数据。前面加一个frame1 <- 就可以删除第一列了。不过想要删除第一列还可以使用 frame1[,1] <- NULL
typeof(frame1$Murder) //用$符号取出来的也是值,可以用typeof()来检验,是double数据框合并:
比如将USArrests和state.division合并为一个数据框
df1 <- data.frame(USArrests, state.division) //可以直接新建一个数据框装这两个数据
cbind(USArrests, state.division) //使用cbind也可以对列进行合并,rbind是对行进行合并,但比较复杂,需要两组数据拥有相同的列修改数据框的值:
使用tranform()函数修改数据框任何列的值,但不胡更改原数据。
transform(women, height = height * 2.54, weight = weight +1) //可以用逗号连接对所有列的操作
transform(women, cm = height*2.54) //原数据是没有cm列的,这个是新加上去的。数据框实际应用:
一个简单的例子,women是数据框类型的数据集。里面包含height和weight两列。
plot(women$height, women$weight) //绘制身高和体重的散点图
lm(weight ~ height, data = women) //线性回归,前面写列名,后面写数据集,在这里weight是因变量,height是自变量,做的线性回归。实际上这里Call的是lm(formula = height ~ weight, data = women)列表:
用 list() 来创建列表。既可以装数字又可以装字符,但结构不清晰。
列表是一维数据的集,列表的对象可以是R中的任何数据结构。
aList <- list(thefirstname=c(1,2,3),thesecond=list(c(1,2,3)),thename=matrix(1:2,1,1,T), disige=x) //名字=数据,可以给数据赋名
dogNumber<-c(1,2,3)
dogName<-c("gougou","zhuzhu","niaoniao")
dogList<-list(dogName,dogNumber)
> dogList
[[1]]
[1] "gougou" "zhuzhu" "niaoniao"
[[2]]
[1] 1 2 3访问列表:
dogNumber<-c(1,2,3)
dogName<-c("gougou","zhuzhu","niaoniao")
dogList<-list(dogName,dogNumber)
dogList[1] //输出的是子集,还是列表
dogList[[1]] //输出的是元素本身。
[1] "gougou" "zhuzhu" "niaoniao"
dogList[[2]]
[1] 1 2 3
dogList[c(1,2)] //同时访问两个元素,需要用向量
state.center["x"] //通过名字来访问列表
state.center$x //通过名字来访问列表
dogList[5] <- "aaa" //列表赋值
dogList[1] <- NULL //删除列表第一个元素单双括号:
> typeof(list1[1]) //单括号取的是第一列
[1] "list"
> typeof(list1[[1]]) //双括号取的是第一列的值
[1] "double"因子:
变量的类型:
- 名义型变量 如城市名
- 有序型变量 如good better best
- 连续型变量 某范围的任意值,如身高等
在R中名义型变量和有序型变量称为因子,factor,这些分类变量的可能值称为一个水平,level,例如good, better, best都称为一个level。因子应用于计算频数、独立性检验、相关性检验、方差分析、主成分分析、因子分析等等。
举个例子:
> mtcars$cyl //mtcars中cyl这一列都是这种有重复的像是可以做分类的数据
[1] 6 6 4 6 8 6 8 4 4 6 6 8 8 8 8 8 8 4 4 4 4 8 8 8 8 4 4 4 8 6 8 4
> table(mtcars$cyl) //那么用table函数可以给它分个类,还有每一类的频数
4 6 8
11 7 14
使用factor()函数,获得一列数据的factor
f <- factor(c("red","red","blue","green","red","blue","green","blue")) //全部的blue\red\greend都是factor,那么levels就是red blue green,也可以自己在factor()中定义level
f <- factor(c("Mon","Tue","Tue","Mon","Wed","Thu","Fri","Sat","Sun"), ordered = T, levels = c("Mon","Tue","Wed","Thu","Fri","Sat","Sun"))
输出加了顺序的结果,因为ordered=T,而且还规定了levels
[1] Mon Tue Tue Mon Wed Thu Fri Sat Sun
Levels: Mon < Tue < Wed < Thu < Fri < Sat < Sun在绘图中,factor和向量,绘出的图不一样。
plot(mtcars$cyl)
plot(factor(mtcars$cyl)) //转换成factor类型,输出下面的柱状图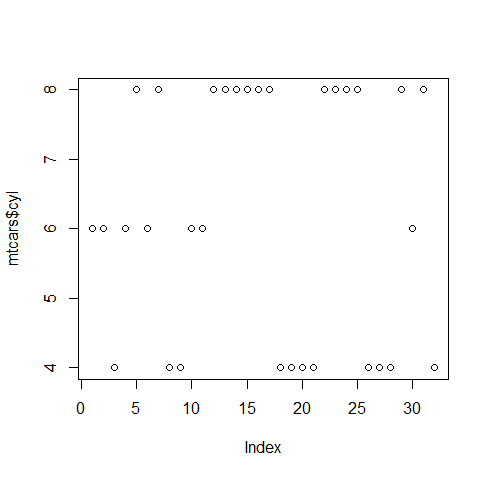
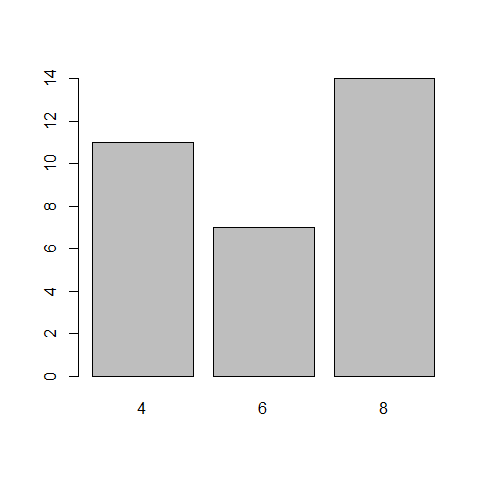
时间和日期:
要把字符串转变成日期,需要加format。
a <- "2021-01-01"
as.Date(a, format = "%Y-%m-%d") //没有赋值给a,这个类型是Date
class(as.Date(a, format = "%Y-%m-%d")) //format的具体格式,可以用help("strftime")函数查看
a <- as.Date(a, format = "%Y-%m-%d") //给a加一个format,再赋值给a
seq(as.Date("2021-01-01"), as.Date("2021-03-01"), by = 10) //规定时间起点和终点,设一个差值,求出时间点。和等差序列类似。
输出
[1] "2021-01-01" "2021-01-11" "2021-01-21" "2021-01-31" "2021-02-10" "2021-02-20"生成时间序列数据:
sales <- round(runif(48,min = 50, max = 100))
ts(sales, start = c(2010,5), end = c(2014,4), frequency = 1) //frequency=1时,就是以年为间隔,=12时就是以月为间隔,=4时就是季度为间隔
输出
Time Series:
Start = 2014
End = 2017
Frequency = 1
[1] 69 88 93 51# 记录一些基本操作
查看数据类型:
- class() 函数查看数据结构,如vector、matrix、array、dataframe、list
- mode() 函数查看元素类型,如数值型、字符型等
- typeof() 函数查看元素类型,比mode更细分,比如数值型的double
工作目录:
getwd() //查看当前工作目录
setwd(dir = "D:/TEST/TEST") //设置工作目录
dir() //查看当前工作目录的文件
ls() //查看当前环境中有哪些变量。但查看不了以.开头的文件,因为在Unix中以.开头的文件是隐藏文件
ls(all.names = TRUE) //这样就可以查看以.开头的文件了
ls.str() //查看当前环境变量的详细信息
str() //查看某个变量的详细信息。可以查看.开头的变量。
rm(x) //删除x变量
rm(list=ls()) //删除当前环境所有变量
save.image() //保存工作空间赋值:
x<<-5
给全局变量x赋值
x<-5
给变量x赋值基本数学操作:
x <- sum(1,2,3,4,5)
求1,2,3,4,5的和并赋值给x
x <- mean(1,2,3,4,5)
求1,2,3,4,5的平均值并赋值给x查看包的帮助和包所带的数据:
data(package="MASS") //查看包所带的数据集
ls("package:MASS") //列出MASS包所有函数
查看帮助:
help(sum) //查看sum函数的帮助信息
?sum //查看sum函数的帮助信息
args(sum) //查看sum函数的参数
example(mean) //查看sum函数的一个示例,也可以查绘图函数的示例
demo(graphics) //查看一个demo
vignette("xts") //查看xts包的pdf文档,但不是每个包都有
help.search("heatmap") //本地搜索heatmap函数
apropos("sum", mod="function") //列出所有包含sum关键字的函数。可以调整mod
RSiteSearch("matlab") //比较老的包不支持help的,就去官网搜索。这个方法会打开浏览去去官网搜索。查看包的方法:
使用 methods() 函数来查看它的所有方法。
methods(is) //查看is的所有方法
methods(as) //查看as的所有方法# 记录一些函数
查看数据维度:
使用 dim() 函数来获取矩阵的行和列,dimension,维度的意思。
matrix1 = matrix(c(1,2,3,4,5,6,7,8,9,10,11,12), nrow = 4, ncol = 3, byrow = T)
dim(matrix1)
输出
[1] 4 3查看数据集的基本信息:
使用 summary() 函数来获取数据集的基本信息。
summary(mtcars)
注意不要加引号,加了引号就变成字符串了。
mtcarsPart = mtcars[,c("gear","wt")]
lmResult = lm(gear~wt, data = mtcarsPart) //如果输出这个结果,就只有Intercept和相关系数。
summary(lmResult) //输出的结果更详细数学函数:
abs(x) //取x的绝对值
sqrt(x) //取x的平方根
log(16, base=2) //以2为底,求16的对数
log(16) //以e为底,求16的对数
log10(16) //以10为底,求16的对数
exp(x) //计算x向量中每个元素的指数
ceiling(x) //对每一项求不小于该项的最小整数
floor(x) //对每一项求不大于该项的最大整数
trunc(x) //求每一项的整数部分
round(x, digits=2) //四舍五入,保留两位小数
signif(x, digits=2) //保留两个有效数字
sin(x) //三角函数
sum(x) //求和
min(x) //取最小值
max(x) //取最大值
range(x) //返回最大值和最小值
mean(x) //取均值
var(x) //求方差
sd(x) //求标准差
prod(x) //求连乘的积
median(x) //求中位数
quantile(x) //求四分位数
which(x==1) //求1所在的位置,即索引值
which.max(x) //求x向量中最大值所在的位置,也就是索引值。数据分组:
使用 cut() 函数来对数据进行分组。
num <- 1:100 //创建一个1到100的向量,现在想分为1-10,21-30,31-40...
cut(num,c(seq(0,100,10))) //seq(0,100,10)得到的是0到100等差为10的等差数列的值,然后按照这些值来对num进行分组生成随机数:
使用 runif() 函数生成随机数,一般不会生成整数,所有用个 round() 函数来对生成的数四舍五入。
round(runif(50, min = 0, max = 100)) //50是生成的随机数个数,0和100是生成随机数的区间检查重名元素:
使用 duplicated() 函数来检查重名情况。然后进行后续操作。
比如 data1 数据中有重复的部分
duplicated(data1) //检查重复的部分 输出TRUE TRUE FALSE FALSE TRUE FALSE FALSE...
data1[duplicated(data1),] //输出重复的部分
data1[!duplicated(data1),] //取反,输出不重复的部分
如果只是想获得非重复的部分,可以使用unique()函数
unique(data1)apply()、lapply()、sapply()、tapply()函数:
apply()可以快速对矩阵、数据框的每一行或每一列进行各种计算。适用于数据框和矩阵
apply(WorldPhones, MARGIN = 1, FUN = sum) //当MARGIN = 1时,表示对每一行进行FUN的函数。当MARGIN = 2时,表示对每一列进行FUN函数。
apply()返回值是数据框
lapply()的返回值是list,适用于list
lapply(state,center, FUN=length) //计算列表的长度。因为列表没有行,所以不用设置MARGIN
sapply()是lapply的简化版
tapply()函数处理因子数据,根据因子分组,然后每组分别处理
tapply(state.name, state.division, FUN=length) //第一个参数是数据集,第二个参数是因子。用因子对第一个数据进行分组,然后进行FUN函数运算。
这行代码会输出每一个division包含几个州 抽样:
使用 sample() 函数来抽样。
?sample
x <- 1:1000
sample(x = x, 500, replace = T) //若replace = T,则是有放回的抽样
用sample()对数据框进行抽样
Orange[sample(Orange$Tree, 20, replace = T),] //还是注意这个逗号,这个列是随便取的,不影响我们对行的抽样# 内置数据集
使用 data() 可以查看自带的数据集。若一不小心数据集被覆盖了,则可以使用 data(“rivers”) 来重置数据集,这里以rievrs举例。
help("mtcars") //查看数据集详情# 处理缺失数据
在R中用NA表示不可用,用来存储缺失信息。NA表示没有,不是表示0。R中对NA的判断和人是一样的。1+NA还是NA。如果一组数据有NA,那么这个数据的Sum,Means都是NA,所以在计算时要处理这些数据。
还有,NaN代表不可能的值,inf代表无穷。
查看是否有NA、NaN、Inf:
使用 is.na() 函数来看数据是否包含NA。使用 is.nan() 函数来看数据是否包含不可能的值。使用 is.infinite() 函数来看数据是否包含无穷的值。
is.na(c(NA,1,1,2,3))
输出
[1] TRUE FALSE FALSE FALSE FALSE
is.nan()
is.infinite()计算时处理NA值:

使用 na.rm 参数来处理计算中的NA。
sum(a, na.rm = TRUE)
mean(a, na.rm = TURE) //求平均值除以的是去掉NA之后的个数使用 na.omit() 函数来处理数据集中的NA。
a <- c(NA,1:10,NA,NA,NA)
b <- na.omit(a)
如果将这个函数运用于数据框,则会把所有包含NA的行都删除掉。# 处理字符串
查看字符串包含的字符个数:
使用 nchar() 函数来判断某字符串包含的字符数。如果某个数据集包含多个字符串,则它会返回每一个字符串的字符数。
将多个字符串合成为一个字符串:
使用 paste() 函数将多个字符串合并成一个字符串,并可以设置分隔符。
paste("I","Love","This","City",sep = "/")
输出
[1] "I/Love/This/City"
如果是向量和字符串相连,则是每个向量值会分别和字符串相连
v1 <- c("hello","world")
paste(v1,"link",sep = "/")
输出
[1] "hello/link" "world/link"
提取字符串:
使用 substr() 函数来提取字符串,包括3个参数。x = 要提取的字符串,start = 提取起始点,stop = 提取到哪里。返回提取到的字符串。
substr(x = month.name, start = 1, stop = 3)
输出
[1] "Jan" "Feb" "Mar" "Apr" "May" "Jun" "Jul" "Aug" "Sep" "Oct" "Nov" "Dec"转换大小写:
使用 toupper() 函数将字符串里的字符转换成大写。使用 tolower() 函数将字符串里的字符转换成小写。如果想替换一个全是小写的字符串为第一个字母大写,则可以使用 sub()、gsub() 函数,gsub()是全局替换,sub()只替换一次。然后里面写正则表达式和perl = T,perl = T表示支持perl类型的正则表达式。用的时候用 help(“gsub”) 查一下帮助。
字符串匹配:
使用 grep() 函数来进行字符串匹配。 目前没搞懂grep() ,可以用 match() 来进行匹配。
x <- c("ABC","BC","ACC")
match(x = x, "BC")
输出
[1] NA 1 NA
讲讲grep()
x <- c("ab","ac","abc","ba")
grep("^a", x = x, perl = T) //这里默认开启了正则表达式,不用输perl = T也是开启了正则表达式的。
输出
[1] 1 2 3
如果输入fixed = T,则就输出0。开启了精准匹配,关闭了正则表达式。字符串分割:
使用 strsplit() 函数来对字符串进行分割。需要设置一个要分割的字符串和一个分隔符。
path1 <- "C:/Users/12/Desktop"
path2 <- "D:/sf/as"
strsplit(c(path1,path2),"/")
输出的是列表
[[1]]
[1] "C:" "Users" "12" "Desktop"
[[2]]
[1] "D:" "sf" "as"有两个字符串,生成它的所有组合,也叫做笛卡尔积:
使用 outer() 来生成两个字符串的所有组合。
x1 <- c("A","B","C","D","E")
x2 <- c(1,2,3,4)
outer(x1, x2, FUN = paste) //这个FUN是function,使用paste来连接。还可以使用sep参数设置连接符号,但这里没演示。
输出
[,1] [,2] [,3] [,4]
[1,] "A 1" "A 2" "A 3" "A 4"
[2,] "B 1" "B 2" "B 3" "B 4"
[3,] "C 1" "C 2" "C 3" "C 4"
[4,] "D 1" "D 2" "D 3" "D 4"
[5,] "E 1" "E 2" "E 3" "E 4"# 数据写入
使用 write() 函数来对文件进行写入。写入文件可以创建新的文件,但是不能创建新的目录。所以要确保目录存在。
写入CSV文件:
使用 write.csv() 函数写入csv文件。
x <- mtcars
write.csv(x, file = "test.csv") //可以设置append参数,若为TRUE,则是追加写入。若是FALSE,则会清空原文件
写为压缩文件:
在 write() 函数里加 gzfile() 等函数进行压缩。
x <- mtcars
write.table(x, gzfile("test.txt.gz"))写入XLS、XLSX文件:
library(xlsx)
write.xlsx2()
具体参数可以查帮助文档存储并写入R格式文件:
存储为R文件会对数据进行自动压缩,并且会保留R元数据,比如因子等。
saveRDS(iris, file = "iris.RDS") //存为RDS文件
save.image() //保存工作空间
save(iris, iris3, file = "test.Rdata") //保存Rdata文件# 数据转换
可以用 is() 函数来判断数据类型。比如is.data.frame(),也可以判断是否为空值 is.na()
R语言中用 as() 函数来转换数据类型。
将数据转换为数据框:
df <- as.data.frame(state.x77)
state.77原来是矩阵、列表的格式。
这种格式,数据要么是字符串,要么就都是数字。格式统一,但数据框可以存不同数据类型的数据。所以从矩阵转到数据框比较容易。
但从数据框转到矩阵就比较麻烦将数据转换为矩阵:
mat1 <- as.matrix(state.region) //搞不懂,nrow和ncol看起来一点用都没有
将向量转换成二维的:
X <- state.abb
dim(x) <- c(5,10) //转换成5行10列的矩阵
as.factor(x) //再把它转换为因子
as.list(x) //再转换成列表。就可以和其他列表构成数据框了将列表转换为向量:
unlist() //用这个函数可以取数据集的子集:
mtPart1 <- mtcars[c(1,2),c(3,2,5)] //取mycars的第1行、第2行的第3、2、5列数据
mtPart2 <- mtcars[c(1:10),c(1:5)] //取mtcars的第1到10行的第1到5列数据
Orange[which(Orange[,"Tree"]==1),] //选择条件来取子集,注意这个逗号,我们不是要取列的值,而是用列值的判断来取行的值,用来取行的
Orange[which(Orange$Tree==1 && Orange$age<=1000),] //用&&来增加条件
另一种取子集的函数: subset()
subset(mtcars, mtcars$vs==0) //参数可以直接写逻辑,就不用加which了数据转置:
Orange
egnarO < t(Orange) //把Orange数据转置了
使用rev()函数对数据进行反转,reverse的意思
rev(rownames(women)) //把women的行名反转了
women[rev(rownames(women))] //再用反转的行名作为索引,得到反转的数据。数据排序:
使用sort()函数对向量进行排序
sort(rivers) //按照数字大小或者字符ASCII大小进行排序
rev(sort(river)) //先排序,后反转
但sort只能用于向量,不能用于数据框。但问题不大,可以对数据框的某列进行排序,然后以此为索引
mtcars[sort(rownames(mtcars)),]
使用order()函数排序返回的是对应值所在的位置,也就是索引。也是排好序了的。
mtcars[order(mtcars$mpg),]
order(mtcars$mpg, decreasing = T) //对上面的结果进行反转,这里不用rev函数。
order()函数还可以对多个列进行排序,比如在某一列值相同的情况下,就看另一列的值大小,然后再排
mtcars[order(mtcars$mpg, mtcars$disp),] //在每加仑行驶里程一样的情况下,排量小的汽车排在前面# 数据处理
数据的中心化与标准化:
数据中心化(零均值化):数据集中各项数据 – 数据集均值
数据标准化(归一化):(数据集中各项数据 – 数据集均值) / 数据集标准差
目的:在多指标评价体系中,由于各评价指标的性质不同,通常具有不同的量纲和数量级。当各指标间的水平相差很大时,如果直接用原始指标值进行分析,就会突出数值较高的指标在综合分析中的作用,相对削弱数值水平较低指标的作用。因此,为了保证结果的可靠性,需要对原始指标数据进行标准化处理。(来源:CSDN)
使用scale()函数来对数据集进行中心化和标准化的操作
scale(state.x77, center = T, scale = T) //center = T 指要做中心化处理,scale = T 指做标准化处理。这里两个参数都写得T,也是做标准化处理。
这个函数,不写center和scale参数,默认都是T,也就是默认做标准化处理。
要做中心化的话,需要把scale参数设置成F。reshape2:
使用reshape2包可以对数据进行融合重铸。先理解两个概念,长数据和宽数据。
长数据:指标类型,需要通过指标来获得的数据。
款数据:笛卡尔积类型数据,是通行行列的交叉点得到的数值。
| 姓名 | 性别 | 语文 | 数学 | 英语 |
|---|---|---|---|---|
| 辣辣 | 男 | 67 | 12 | 12 |
| 啵啵 | 女 | 43 | 54 | 43 |
| 吉吉 | 男 | 87 | 54 | 65 |
| 安安 | 女 | 32 | 65 | 76 |
| 常常 | 女 | 54 | 36 | 54 |
| 卡卡 | 男 | 25 | 86 | 34 |
| 姓名 | 性别 | 科目 | 成绩 |
|---|---|---|---|
| 辣辣 | 男 | 语文 | 67 |
| 啵啵 | 女 | 英语 | 43 |
| 吉吉 | 男 | 语文 | 87 |
| 辣辣 | 男 | 数学 | 12 |
| 辣辣 | 男 | 英语 | 12 |
| 吉吉 | 男 | 英语 | 65 |
使用 melt() 函数将宽数据转换成长数据。使用 dcast() 函数将长数据转换为宽数据。
melt(data, id.vars, measure.vars, variable.name = "variable", .., na.rm = FALSE, value.name = "value")
data: 所选数据
id.vars: 标识变量(不动的那些列)
measure.vars:度量变量(除了表示变量以外的所有变量)
variable.name:对度量变量名这一列进行命名,默认为variable
na.rm:是否删除NA值
value.name:对度量变量的值那一列进行命名,默认为value
用airquality举个例子
melt(airquality) //把宽数据转换成长数据,这是默认情况
aql <- melt(airquality, id.vars =c("Month","Day")) //id.vars写的是月份和天数,剩下的(ozone, solar.r, wind等)都是variable。
那么结果就是月份天数所对应的每一种变量的值的长数据。
输出head(aql)
Month Day variable value
1 5 1 Ozone 41
2 5 2 Ozone 36
3 5 3 Tmp 12
4 5 4 Wind 18
5 5 5 Wind NA
6 5 6 Solar.R 28处理数据框用 dcast() 函数,处理向量矩阵数组就用 acast() 函数
dcast(aql, Month + Day ~ variable) //就把刚才得到的长数据,又转换成之前的宽数据了。
aqw <- dcast(aql, Month ~ variable, fun.aggregate = mean) //但不想转换成之前那种一模一样的宽数据。我只想看Solar.r, Temp, Wind的每个月份的平均值。tidyr:
感觉tidyr中的 gather() 和 spread() 函数和reshape2的 melt() 和 dcast() 函数相似。
使用gather()函数,和reshape2的melt()函数差不多的功能。
mtPart <- mtcars[c(1:20),c(1:4)] //用不到所有数据,截取一段
mtPart <- data.frame(names = rownames(mtPart), mtPart) //将行名添加到数据中
gmtPart <- gather(mtPart, key = "Key", value = "value", mpg:hp) //用冒号就是从mpg到hp的列都要处理,也可以用列的排列序号来指定要处理的列,还可以直接写mpg, cyl, disp, hp这四列
这个key = "" value ="" 都是定义输出结果的列的名字的
gmtPart <- gather(mtPart, key = "Key", value = "value", mpg, cyl) //这里只处理了mpg和cyl两列,还有disp,hp两列没处理
输出
disp hp Key value
1 160.0 110 mpg 21.0
2 160.0 110 mpg 21.0
3 108.0 93 mpg 22.8
spread(gmtPart, key = "Key", value = "Value") //再把刚才的长数据转换成宽数据tidyr包中的 separate() 函数和 unite() 函数的功能恰恰相反。
x <- c(NA,"a,b","A.B","1。2")
df1 <- data.frame(x) //以后尽量对要处理的数据,都整成数据框
separate(df1, col = x, into = c("col1","col2")) //col1、col2是输出的列名,自动检测分隔符。如果分割比较复杂,也可以添加sep参数自己设置分隔符
输出
col1 col2
1 <NA> <NA>
2 a b
3 A B
4 1 2
使用unite()函数将这两列连起来
unite(x, col = "lianqilai", col1, col2, sep = "-")
输出
lianqilai
1 NA-NA
2 a-b
3 A-B
4 1-2dplyr:
dplyr包的函数太多了,功能太丰富了。有些函数的名字和其他包的重复,所以可以用 dplyr::funname 的方式来调用dplyr的函数。
dplyr::filter()函数用来对数据集进行过滤
dplyr::filter(iris, iris$Sepal.Length>7) //选择iris中sepal.length大于7的行。序号从1开始
dplyr::slice(iris,1:10) //取出iris中1到10行数据
dplyr::sample_n(iris,10) //抽样,对iris数据集抽取10行数据
dplyr::sample_frac(iris,0.1) //按比例抽样,比如iris有150行数据,那么这里就抽150*0.1=15条数据
dplyr::arrange(iris,iris$Petal.Length) //按照iris的petallength对iris数据集进行排序
dplyr::arrange(iris,desc(iris$Petal.Length)) //加了个desc(),按照降序排序
dplyr::select() //取子集的函数,用的时候可以参照帮助文档和示例
dplyr::group_by(iris, iris$Species) //通过种类对iris进行分组。
dplyr::mutate(iris, "s+p" = iris$Sepal.Length+iris$Petal.Length) //给iris新增一列"s+p",值为sepalLength+petalLength对双表格的操作:
dplyr::left_join(a,b,by = "x1") //SQL的内容,以左边的表为基础,通过x1这一列来连接
dplyr::right_join(a,b,by = "x1") //以右边的表为基础,通过x1这一列来连接
dplyr::inner_join(a,b,by = "x1")
//取x1的交集
dplyr::full_join(a,b,by = "x1") //取x1的并集
dplyr::semi_join(x,y,by = "x1") //return all rows from x with a match in y.
dplyr::anti_join(x,y, by = "x1") //return all rows from x without a match in y.
dplyr::intersect(x,y) //取x,y的交集
dplyr::union_all(x,y) //取x,y的并集
dplyr::union(x,y) //取x,y非冗余的并集
dplyr::setdiff(x,y) //取x中不同于y的元素
# 数据统计
统计函数:
这里需要统计学基础。
有些函数还是有规律可循的,比如以下列字母开头:
d -> 概率密度函数
p -> 分布函数
q -> 分布函数的反函数
r -> 生成相同分布的随机数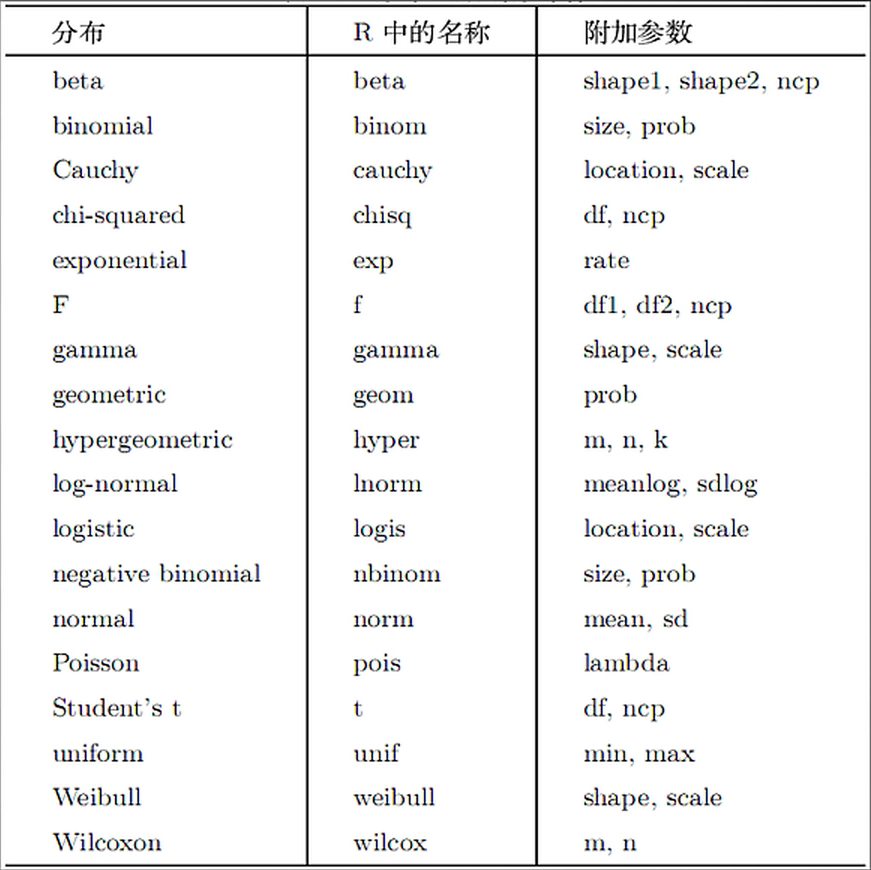
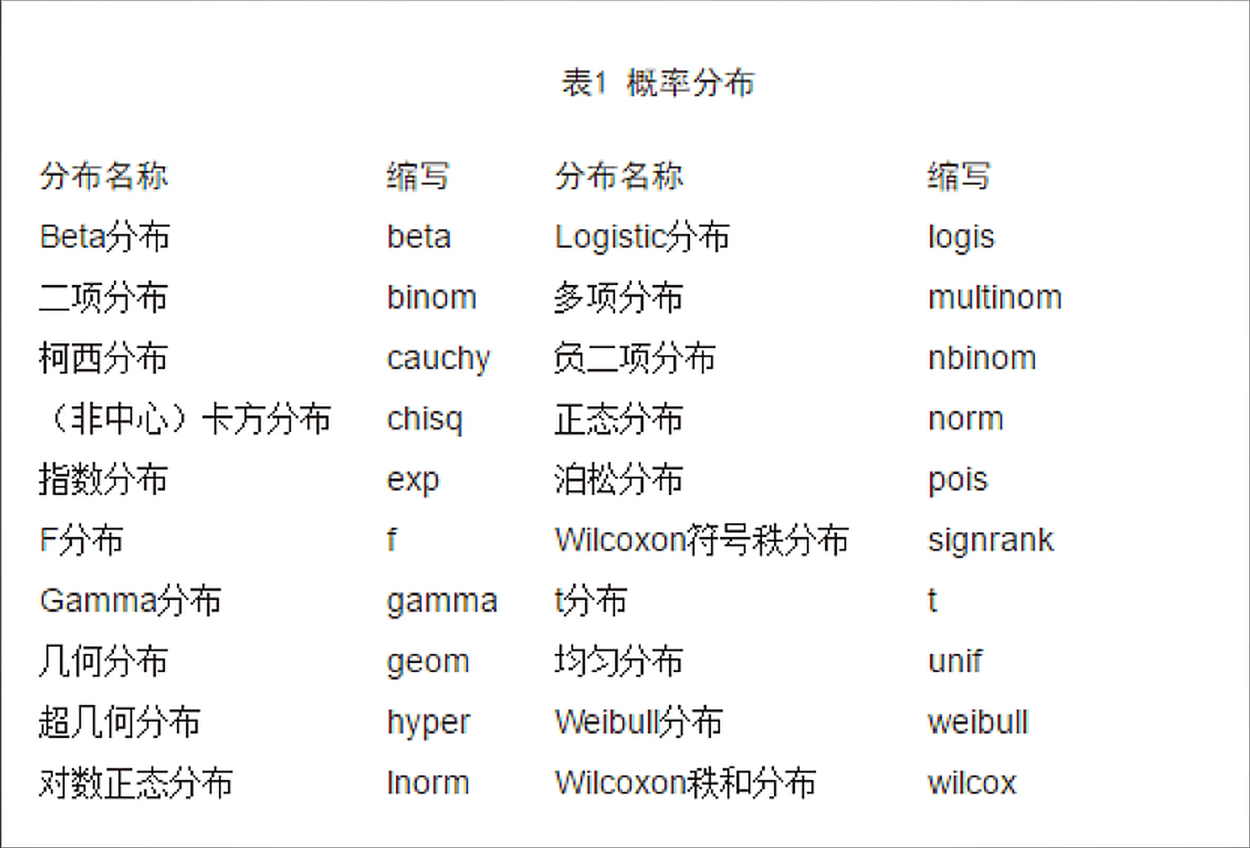
比如想要随机生成符合正态分布的一些数据,就可以找到norm,加上r以表示生成随机数据。那么函数就该选用 rnorm()
描述性统计函数:
使用 summary() 函数可以查看一个数据集数据的整体情况,包括均值、中位数、方差等。
使用 Hmisc::describe() 函数可以查看数据集分位数、平均值、最大值、最小值、缺失值等信息。
使用 stat.desc() 函数也可以查看数据集信息。其中参数可以设置basic = T , desc = F或 desc = T查看不同信息。使用norm = T参数,可以查看关于正态分布的统计量,如偏度峰度等。
使用 psych::describe() 函数计算非缺失值的平均数、中位数、偏度峰度、最大值最小值等内容。这个函数还可以通过设置trim参数去除数据集的一些部分。如trim = 0.1,则是去掉最高和最低10%的部分。
分组统计函数:
使用 aggregate() 函数可以对数据进行分组统计。
x <- aggregate(x = Cars93[c("Min.Price")], by = list("产地" = Cars93$Origin, "制造" = Cars93$Make), mean)
通过产地和制造来对最低价格的平均值进行分组显示
输出:
产地 制造 Min.Price
1 non-USA Acura Integra 12.9
2 non-USA Acura Legend 29.2
3 non-USA Audi 100 30.8
4 non-USA Audi 90 25.9
5 non-USA BMW 535i 23.7
6 USA Buick Century 14.2使用 doBy::summaryBy() 函数来进行分组统计显示。
doBy::summaryBy(Min.Price ~ Origin + Make, data = Cars93, FUN = mean)
通过产地和制造来对最低价格的平均值进行分组显示,比aggregate函数更好用我感觉
输出
Origin Make Min.Price.mean
1 USA Buick Century 14.2
2 USA Buick LeSabre 19.9
3 USA Buick Riviera 26.3
4 USA Buick Roadmaster 22.6
...
78 non-USA Nissan Sentra 8.7
79 non-USA Saab 900 20.3使用 psych::describeBy() 函数来进行分组计算每一组的统计值。
频数统计函数:
可以先用 cut() 函数将数据集进行切割,然后用 table() 函数进行频数统计。
c <- cut(x = mtcars$mpg, c(seq(10,50,10)))
table(c)
输出:
(10,20] (20,30] (30,40] (40,50]
18 10 4 0
这是每一组的频数,这个组是我们刚才用cut()函数人为规定的
然后用prop.table()来求频率值
prop.table(table(c))
输出:
(10,20] (20,30] (30,40] (40,50]
0.5625 0.3125 0.1250 0.0000 如果是二维的表,比如一个实验组一个对照组,那么也可以用 table() 函数实现频数统计。
table(Cars93$DriveTrain, Cars93$Passengers) //统计DriverTrain为4Wd\Front\Rear时,载人数为245678情况的频数
输出:
2 4 5 6 7 8
4WD 0 3 2 0 4 1
Front 0 15 34 14 4 0
Rear 2 5 5 4 0 0同样处理二维的表,也可以用 xtabs() 函数实现频数统计。
xtabs(~ DriveTrain+Passengers, data = Cars93) // ~波浪线表示省略formula,用+连接想统计的值
输出:
Passengers
DriveTrain 2 4 5 6 7 8
4WD 0 3 2 0 4 1
Front 0 15 34 14 4 0
Rear 2 5 5 4 0 0
使用margin.table()函数,分行列来计算总数
rowX <- margin.table(x,1) //计算行的统计值
colX <- margin.table(x,2) //计算列的统计值
使用addmargins()函数将刚才计算的行列统计值加到数据中
addmargins(x)
输出:
Passengers
DriveTrain 2 4 5 6 7 8 Sum
4WD 0 3 2 0 4 1 10
Front 0 15 34 14 4 0 67
Rear 2 5 5 4 0 0 16
Sum 2 23 41 18 8 1 93也可以计算三维列联表,可以用 ftable() 函数将三维列联表转换成平面的,方便看。
独立性检验:
独立性检验是根据次数资料判断两类因子彼此相关或相互独立的假设检验。也称显著性检验,若使用卡方分检验,则χ2越小则独立性越大,否则相关性越大。
检测独立性除了卡方检验,还有Fisher检验、Cochran-Mantel-Haenszel检验等。
那么这里就涉及到假设检验了。可以做一个零假设:变量是独立的,备择假设:变量不是独立的。然后检测其显著性来判断拒绝或接受零假设。
P-value则是在原假设为真时,得到最大的或超出所得到的检验统计量的概率值。当p<0.05时,拒绝零假设。
卡方检验:
tab1 <- table(Arthritis$Treatment, Arthritis$Improved)
chisq.test(x = tab1) //chisq.test()函数要求输入为一个matrix或者输入两个都为vector的参数。
输出:
Pearson's Chi-squared test
data: tab1
X-squared = 13.055, df = 2, p-value = 0.001463
这里的p值为0.00146,小于0.05,则拒绝零假设(变量是独立的),接受备择假设(变量是有关系的)
tab1
输出:
None Some Marked
Placebo 29 7 7
Treated 13 7 21费舍尔精确检验:
Fisher Exact Test是检测边界固定的列联表中,它的行和列是否是相互独立的。
那么就不能使用table()函数来整合数据了,要用xtabs()函数整合数据为列联表。
xtab1 <- xtabs(~Arthritis$Treatment+Arthritis$Improved, data = Arthritis)
fisher.test(xtab1)
xtab1
输出:
Arthritis$Improved
Arthritis$Treatment None Some Marked
Placebo 29 7 7
Treated 13 7 21Cochran-Mantel-Haenszel检验:
用于检验重复测量两离散变量的独立性。通常使用 2x2xK 列表表示,K是测量条件的次数。比如你想要指导是否一个处理(C vs. D)是否影响了恢复的概率(yes or no)。假设该处理一天监控测量三次——早上、中午和晚上,而你想要你的检验能够控制它。那么你可以使用 CMH 检验对 2x2x3 列联表进行操作,第三个变量是你想要控制的变量。(来源:Cookbook for R)
因为要用到计数的数据框,所以也用 xtabs() 函数将数据转换成计数的形式。
ct <- xtabs(Count ~ Allele + Habitat + Location, data = fish) //最后一个变量是要控制的变量。
mantelhaen.test(ct) //CMH检验的函数相关性分析函数:
相关性分析是指对两个或多个具备相关性的变量元素进行分析,从而衡量两个变量因素的相关密切程度。相关性的元素之间需要存在一定的联系或者概率才可以进行相关性分析。
相关性有正相关、负相关和不相关。可以使用Pearson相关系数、Spearman相关系数、Kendall相关系数、偏相关系数、Polychoric相关系数、Polyserial相关系数等指标来衡量正负相关性。
进行相关性分析没有那么多函数,可以用 cor() 函数来计算相关性。
?cor //查看帮助文档,发现有个method参数,不设置method参数默认是Pearson相关性分析。可以设置成kendall、spearman
cor(state.x77, method = "pearson") //对state.x77数据集进行一个pearson相关性分析。结果会有很多-1~1的值
怎么看这些值?
Pearson相关系数:0.8~1是极强相关,0.6~0.8是强相关,0.4~0.6是中等程度相关,0.2~0.4是弱相关。正的就是正相关,负数就是负相关。
当然Pearson也可以检验不同列的相关性。
x <- state.x77[,c("Income", "Illiteracy", "Frost")]
y <- state.x77[,c("Murder", "Area")]
cor(x = x, y = y, method = "pearson")
输出:
Murder Area
Income -0.2300776 0.36331544
Illiteracy 0.7029752 0.07726113
Frost -0.5388834 0.05922910协方差:
协方差(Covariance),可以反应两个随机变量的相关程度。如果这两个变量变化趋势一致,则为正值。如果变化趋势相反,则为负值。看协方差和Pearson相关系数公式可以发现,Pearson相关系数是由协方差除以两个变量的标准差得到的。而且在计算偏相关的时候,也要用到协方差的结果。使用 cov() 函数来计算协方差。
偏相关:
偏相关分析是指当两个变量同时与第三个变量相关时,将第三个变量的影响剔除,只分析另外两个变量之间相关程度的过程,判定指标是相关系数的R值。
p值是针对原假设H0:假设两变量无线性相关而言的。一般假设检验的显著性水平为0.05,你只需要拿p值和0.05进行比较:如果p值小于0.05,就拒绝原假设H0,说明两变量有线性相关的关系,他们无线性相关的可能性小于0.05;如果大于0.05,则一般认为无线性相关关系,至于相关的程度则要看相关系数R值,R越大,说明越相关。越小,则相关程度越低。
ggm::pcor(u, s) //使用ggm包的pcor()函数来计算偏相关系数。
colnames(state.x77) //看列明对应的序号,因为proc参数需要用到序号
ggm::pcor(c(3,5,1,2), cov(state.x77)) //3, 5是要计算相关性的两列,后面的1,2是条件变量。后面跟一个数据的协方差。相关性检验函数:
做完相关性分析后得到的相关系数,还是需要使用p-value来检验的,检验后就能给个置信区间来相信这个相关系数了。那么这里又涉及到假设检验了。零假设是无效假设。
使用cor.test()函数进行相关性检验,使用该函数进行相关性检验,则零假设都是相关性为0.
cor.test(state.x77[,3], state.x77[,5]) //检验state.x77第三列文盲率和第5列谋杀率的相关性。可以更改method参数来选择pearson或者spearman等计算方式,具体看帮助文档
输出:相关性系数为0.7029752,p-value是1.258e-08
Pearson's product-moment correlation
data: state.x77[, 3] and state.x77[, 5]
t = 6.8479, df = 48, p-value = 1.258e-08
alternative hypothesis: true correlation is not equal to 0
95 percent confidence interval:
0.5279280 0.8207295
sample estimates:
cor
0.7029752 使用 cor.test() 函数只能进行一次相关性检验。不过使用 psych::corr.test() 可以进行递归处理,进行多次相关性检验,并且给出两个矩阵分别显示相关性系数和p-value。
psych::corr.test(state.x77, method = "pearson")
输出:
Population Income Illiteracy Life Exp Murder HS Grad Frost Area
Population 1.00 0.21 0.11 -0.07 0.34 -0.10 -0.33 0.02
Income 0.21 1.00 -0.44 0.34 -0.23 0.62 0.23 0.36
Illiteracy 0.11 -0.44 1.00 -0.59 0.70 -0.66 -0.67 0.08
Life Exp -0.07 0.34 -0.59 1.00 -0.78 0.58 0.26 -0.11
Murder 0.34 -0.23 0.70 -0.78 1.00 -0.49 -0.54 0.23
HS Grad -0.10 0.62 -0.66 0.58 -0.49 1.00 0.37 0.33
Frost -0.33 0.23 -0.67 0.26 -0.54 0.37 1.00 0.06
Area 0.02 0.36 0.08 -0.11 0.23 0.33 0.06 1.00
Sample Size
[1] 50
Probability values (Entries above the diagonal are adjusted for multiple tests.)
Population Income Illiteracy Life Exp Murder HS Grad Frost Area
Population 0.00 1.00 1.00 1.00 0.23 1.00 0.25 1.00
Income 0.15 0.00 0.03 0.23 1.00 0.00 1.00 0.16
Illiteracy 0.46 0.00 0.00 0.00 0.00 0.00 0.00 1.00
Life Exp 0.64 0.02 0.00 0.00 0.00 0.00 0.79 1.00
Murder 0.01 0.11 0.00 0.00 0.00 0.01 0.00 1.00
HS Grad 0.50 0.00 0.00 0.00 0.00 0.00 0.16 0.25
Frost 0.02 0.11 0.00 0.07 0.00 0.01 0.00 1.00
Area 0.88 0.01 0.59 0.46 0.11 0.02 0.68 0.00偏相关检验:
进行偏相关检验,则使用 ggm::pcor.test() 函数。
x <- ggm::pcor(c(1,5,2,3,6), cov(state.x77)) //进行检验,要先获得协相关系数
ggm::pcor.test(x, 3, 400) //三个参数分别为,协相关系数、条件变量数、样本数
输出:
$tval
[1] 7.335868
$df
[1] 395
$pvalue
[1] 1.261505e-12T检验:
主要用于样本含量较小(例如n < 30),总体标准差σ未知的正态分布。t检验是用t分布理论来推论差异发生的概率,从而比较两个平均数的差异是否显著。它与f检验、卡方检验并列。
t.test(Prob ~ So, data = UScrime) //Prob是进监狱的概率,So表示是否为南方的州。
输出:p-value为0.00065,则拒绝零假设(美国南北方进监狱概率没有区别)
Welch Two Sample t-test
data: Prob by So
t = -3.8954, df = 24.925, p-value = 0.0006506
alternative hypothesis: true difference in means between group 0 and group 1 is not equal to 0
95 percent confidence interval:
-0.03852569 -0.01187439
sample estimates:
mean in group 0 mean in group 1
0.03851265 0.06371269 非参数检验:
非参数检验是在总体方差未知或知道甚少的情况下,利用样本数据对总体分布形态等进行推断的方法。由于非参数检验方法在推断过程中不涉及有关总体分布的参数,因而得名为“非参数”检验。
参数检验:
指对参数平均值、方差进行的统计检验。参数检验是推断统计的重要组成部分。当总体分布已知(如总体为正态分布),根据样本数据对总体分布的统计参数进行推断。
# 绘图函数
调用基础的 plot() 和 par() 函数就可以绘制大部分图了。
使用 plot() 函数输入不同类型数据,绘制不同的图。
par() 是用来设置图像的各种参数的,如轴的长度、外边距、字号等。plot(as.factor(mtcars$cyl, col = c("red", "blue", "green"))) // col - ...是par的参数# 自定义函数
fun1 <- function(args){
...
...
return(c(x,y...)) //返回值
}
写一个取非NA的值的函数
fun1 <- function(x){
y <- x[!is.na(x)]
return(y)
}
noNAData <- fun1(myDataV)//调用这个函数循环:
for(i in 1:10){
print(i)
} //这是for循环,不知道怎么加判断。不过不用定义i
i <- 1
while(i < 10){
print(i)
i <- i+1
} //这是while循环,需要定义i判断:
i <- 1
if(i<2){
print("i小于2")
}else{
print("i不小于2")
} //if判断
R中Switch判断好怪,不学了# 笔记
参数可以做很多事:
比如 sep 参数,可以设置成”/t”,就可以以tab键作为分隔符。
函数的参数:
函数可能会让你输入很多参数,参数命名是由规律的。
一般来说x表示对象,file表示文件,data表示数据框,三个点表示省略或者与其他函数一致,na.rm表示是否移除NA值。
调节参数就要参考这个包的这个函数的帮助文档了。
关于R中的符号:
