Python数据预处理御用模块。
# 序
pandas 意为诸多熊猫,能够召唤一群熊猫来捣鼓数据。参考极客鸭geekDuckKonig的视频讲解。
# 基础操作
使用字典 dict 创建DataFrame
# 定义字典
df_dict = {
'col1': [1, 2, 3, 4, 5],
'col2': ['one', 'two', 'three', 'four', 'five'],
'col3': ['一', '二', '三', '四', '五'],
'col4': ['I', 'II', 'III', 'IV', 'V']
}
# 调用.DataFrame()方法初始化一个DF表格
df = pandas.DataFrame(df_dict)
# 将DF转回字典
df_to_dict = df.to_dict()
# 访问列索引
df_columns_index = df.columns
'''
Index(['col1', 'col2', 'col3', 'col4'], dtype='object')
'''
# 将Index转为list
df_columns_list = df.columns.tolist()
df_columns_list = df.columns.to_numpy()
# 访问行索引
df_rows_index = df.index指使用二维列表创建DataFrame
vif_rows_array = [[11, 11, 11, 11, 11], [22, 22, 22, 22, 22, 22], [33, 33, 33, 33, 33]]
vif_df = pandas.DataFrame(vif_rows_array, index=['idx_1', 'idx_2', 'idx_3'], columns=['tmx', 'tmn', 'tem', 'mn', 'pre'])
指定或改变索引
# 重新赋值行索引
df.index = ['i1', 'i2', 'i3', 'i4', 'i5']
# 重新复制列索引
df.columns = ['c1', 'c2', 'c3', 'c4']
# 仅更改某一个列名/索引
df = df.rename(columns={'col1': 'c1'})
# 用dict创建DF时,设定(创建)行索引
df = pandas.DataFrame(df_dict, index=['day1', 'day2', 'day3', 'day4', 'day5'])
访问DataFrame
# 访问一列,返回的是Series
df['col1']
# 访问一列或多列,返回的是DataFrame
df[['col1']]这里需要提到 .loc() 与 .iloc() 的区别,前者是基于行和列的label,后者基于行和列的整数位置。
# 使用.loc[]基于行和列的Label来访问数据。下面代码为访问标签为'day1'的行的标签为'col2'和'col1'的列的数据
df.loc['day1', ['col2', 'col1']] # 返回Series
df.loc[['day1'], ['col2', 'col1']] # 返回DataFrame
# 使用.iloc[]基于行和列的位置来访问数据。下面代码为访问第1行的第二列和第一列的数据
df.iloc[0, [1, 0]] # 返回Series
df.iloc[[0], [1, 0]] # 返回DataFrame
# 使用.iloc[]访问多个行多个列的内容
df.iloc[0:1, 0:3] # 返回Series还是DataFrame取决于数据的维度,若行或列均有多个元素,则为DataFrame,否则为Series
# 使用.at[]或iat[]访问具体的某个元素
df.at['day1', 'col3']
df.iat[0, 2] # 同上导入数据到DataFrame
# 通过读取csv、excel、html、json、xml等数据至DataFrame
# header指的是以第几行为表头,默认为0(第一行),None表示没有表头。index_col指以第几列为index,默认None。usecols指传入哪几列
df = pandas.read_excel('test.xlsx', sheet_name='Sheet1', header=None, index_col=0, usecols=[1, 2])
# 还有dtype可以设置数据类型,true/false_values设置哪些值为真/假,skiprows指定跳过哪些行可以配合匿名函数,nrows指定传入哪些行,以及NA值过滤等。
# https://pandas.pydata.org/docs/reference/api/pandas.read_excel.html
# 查看行列数
df.shape
# 查看前n行
df.head(n)
# 查看后n行
df.tail(n)
# 任返n行数据
df.sample(n)查看数据的分布、类型、占据内存
# 查看每列数据的分布
df.describe()
# 查看表格索引、列的类型、占据内存
df.info()
# 查看每列的类型
df.dtypes # 每种类型如下图所示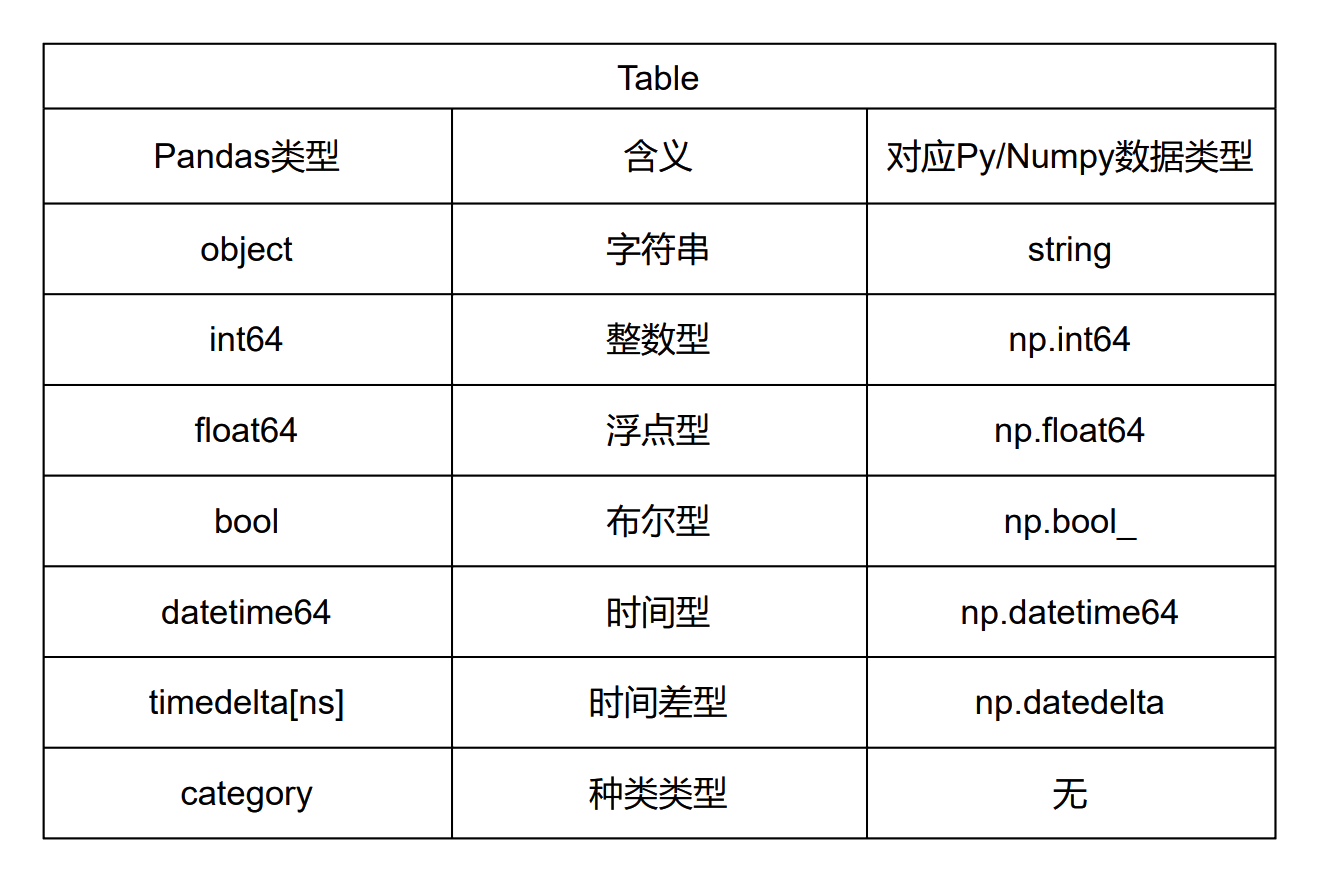
唯一值
# 一列Series中的唯一值
df['colname'].unique()
# 一列Series或一个DataFrame中唯一值的个数。返回每一列唯一值的个数。
df.nunique()分类统计
# 按照省份统计各省百强县个数,虽然是count计数然而列名还是之前的列名“县市”
各省百强县个数 = df[['省份', '是否百强县', '县市']].groupby(['省份', '是否百强县']).count()
# 上面通过两个列来归类,因此这两个列成了一个多级索引。使用.reset_index()将成为多级索引的列重新变回列
各省百强县个数 = 各省百强县个数.reset_index()
各省百强县个数 = 各省百强县个数.rename(columns = {'县市': 'count'})
# 通过.set_index()可以重新构建多级索引
各省百强县个数 = 各省百强县个数.set_index(['省份', '是否百强县'])
动态选择记录
# age不为Null的行
filter_param = (~df['age'].isnull())
df.loc[filter_param, :]
~为取反,&为取和,|为取或QGIS 内也有类似的合成函数,把多个图层多个功能融合在一起得到结果。这里图层变成坐标轴了。合成函数
def percentile_25(x):
return x.quantile(0.25)
aggregation = df[['省份', '是否百强县', '县市']].groupby(['省份', '是否百强县']).agg(['min', 'max', 'median', 'mean', len, numpy.std, percentile_25])Series三大属性
# DataFrame中的一行或一列都可以表示为Series
# 三大属性分别是name、values以及index
df.iloc[0, :].name
df.iloc[0, :].values
df.iloc[0, :].index删除某列或某些列的数据
# del
del df['col1']
# 删除某列并返回该列的Series
del_series = df.pop['col1']
# 使用.drop()时需要注意inplace参数。inplace默认为False,意为不改变原数据,改变后的数据被返回
df.drop(['col1', 'col2'], axis=1, inplace=True) # 当inplace为True时,意味没有返回值直接修改原数据
# 若不想指定axis,则指定columns
df.drop(columns=['col1', 'col2'], inplace=True)
# 按照数字顺序删除某些列,注意axis=1
data_df.drop(data_df.columns[1], axis=1, inplace=True)删除某行或某些行的数据
需要注意的是, .drop() 了这些行之后,索引也一并删除了。剩下的值索引还是原来的索引。想重新从〇开始索引的话得 .reset_index() 。
# 删除第一行的数据
df.drop(0, inplace=True)
# 删除第一二三行的数据
df.drop([0, 1, 2], inplace=True)
df.drop(index=[0, 1, 2], inplace=True)更改DataFrame内某个特定位置的值
# 使用.at[],而不能用.loc[]
df.at[index', column] = 1
# 工作流
pandas 提供了大量字符串处理的方法。字符串预处理
# 将所有string变为小写
df['house'] = df['house'].str.lower()
# 将所有string变为大写
df['house'] = df['house'].str.upper()
# 得到每个字符串的字符数
df['gender'].str.len()
# 连续使用多个字符串处理函数
df['house'].str.lower().str.replace('.', '_')
# 利用split()方法获取逗号之前的值。如果最后不加str[0],则得到内含分割后列表的列表。str[0]为列表内每一个列表第一个元素。
df['house'].str.split(',').str[0]
# 如果[0]跟在split()后面,则返回第一个被分割的元素的列表,为[I,1]
df['house'].str.split(',')[0]
# 字符串拼接
df['house_gender'] = df['house'] + '_' + df['gender']使用自定义函数
根据功能 def 自定义函数实现复杂功能,使用 .apply() 作用于每一行(列)数据上。
def field_calculate(df_param):
province_name, city_name, ranking, pop = df_param['pn'], df_param['cn'], df_param['rk'], df_param['pop']
return_str = '{}{} with the population of {} is ranked {}'.format(province_name, city_name, pop, ranking)
return return_str
# axis=1时为列,axis=0时为行
df['comment'] = df.apply(field_calculate, axis=1)
# 当功能没那么复杂,也可以使用匿名函数。下述代码为判断每一行'salary'属性值是否大于3000,若是则填入yes,否则填no。
df['over_3k_or_not'] = df.apply(lambda x: ('yes' if x['salary'] > 3000 else 'no'), axis=1) # 注意axis。还有一个三元表达式
df['salary+3000'] = df.apply(lambda x: x['salary'] + 3000, axis=1) # 工资+3000
时间信息的处理
# 定义一个时间戳,利用format参数定义格式
timestamp = pandas.to_datetime('2000-1-1', format='%Y-%m-%d')
'''
2000-01-01 00:00:00
'''与字符串处理类似, pandas 也提供了大量时间数据处理的方法。
taxi['pick_up_dt'] = pandas.to_datetime(taxi['pick_yp'])
taxi['drop_off_dt'] = pandas.to_datetime(taxi['drop_off'])
taxi['duration'] = taxi['drop_off_dt'] - taxi['pick_up_dt']
# 将时间差转为秒
taxi['sec'] = taxi['duration'].dt.seconds
# 得到时间是否在周末的信息
# 0~4 for Monday to Friday respectively, 5 for Saturday and 6 for Sunday
taxi['is_weekend_or_not'] = taxi['pick_up_dt'].dt.weekday >= 5 # If true return True时间筛选
与上面动态选择记录相似,但是这里补充了更多信息。
t_filter1 = (taxi['pick_up_dt'] >= time_start) & (taxi['pick_up_dt'] < time_end)
t_filter2 = (taxi['drop_off_dt'] >= time_start) & (taxi['drop_off_dt'] < time_end)
# 使用.to_timedelta()可以得到相应时间的时间差
t_filter3 = (taxi['duration'] <= pandas.to_timedelta('3hour')) & (taxi['duration'] >= pandas.to_timedelta('1min'))
taxi = taxi.loc[t_filter1 & t_filter2 & t_filter3, :]根据列名筛选出新DataFrame
feature_col_names = [col_name for col_name in train_data.columns if col_name not in ['SalePrice']]
train_features = train_data[feature_col_names]split-apply-combine
学习 R 的时候很难搞清楚这些复杂操作流程 process ,一年半过去了,感觉已进入似懂非懂的状态。该流程分类数据、分类后处理数据并合并或总结数据信息。
# 根据上车地点编号集计平均出行时长
def mean_traveltime_mins(x):
return x['sec'].mean() / 60
taxi.groupby(['PULocationID']).apply(mean_traveltime_mins)
# .filter()根据上车地点ID和是否周末集计,只选取出行次数大于500个的集计分组中的记录
def min_filter(df, min_trips):
if len(df) <= min_trips:
return False
else:
return True
taxi_filtered = taxi.groupby(['PULocationID', 'is_weekend_or_not']).filter(min_filter, min_trips=500)使用Series一次拓展多个列
def mean_traveltime_df(df):
return pandas.Series({'mean_tt': df['sec'].mean() / 60, 'median_tt': df['sec'].median() / 60, 'count': len(df)})
time_sum = taxi.groupby(['PULocationID', 'is_weekend_or_not']).apply(mean_traveltime_df).reset_index()表格排序
# 按照列的值进行排序。按'mean_tt'列以降序排列。
time_sum.sort_values('mean_tt', ascending=False) # ascending默认为True,意味升序
# 按照列的值排列返回排名。按'mean_tt'列以降序排列返回排名
time_sum['mean_tt_rank'] = time_sum['mean_tt'].rank(ascending=False) # ascending同上
# 按照索引值的大小排列。在没有改变索引的情况下想恢复原始排序
time_sum.sort_index()
无法在排完序的df中使用.loc[]定位的解决方案
# 转换成ndarray再使用idx来选择元素
gini_data = gini_data.sort_values('rslt_nt_hn', ascending=True)
for i in range(len(gini_data)):
if i < 100:
if gini_data['is_hn'].values[i] == 1:
ax.plot(gini_data['cumulative_pop'].values[i:i+2], gini_data['cumulative_access'].values[i:i+2], color='red', linewidth=2)表格拼接
有三种方法可以进行表格拼接,每一种方法拼接依据不同。
.concat() :按照行或列的方向简单拼接pandas.concat([df1, df2], axis=0) # axis为0时意为把多行数据拼接起来(竖向)。为1时意味把多列数据拼接起来(横向)Left Join:以左边DF为基准进行join,join后的表的行数与左边DF一致。
# Left Join,两张表不存在同名列。按两张表0,1,2,3...的默认索引进行Join
df = df.join(other_df, how='left') # how默认为left
# Left Join,两张表存在同名列,后缀设置一张表的即可,也可以两张表都设置。按两张表0,1,2,3...的默认索引进行Join
df = df.join(other_df, lsuffix='_l', rsuffix='_r')
# 上面两种情况实际上均以DataFrame的默认index为索引(0,1,2,3...)进行Join。
# 若想指定按照某两列的值进行Join,如同QGIS的join table,则需要手动设置Index
# on设置以哪一列为df(left)的index,需要使用.set_index()指定other_df的索引,否则以默认索引来匹配on=指定的df的索引
df = df.join(other_df.set_index('ID'), on=['IA']) # Join后只剩一个ID字段了,不存在重名字段,无需设置后缀
# 上面这样做的好处是,.set_index()是临时的,仅用于此次join。而视频中的操作改变了原表的index。
# 数据如下字典所示
df_dict = {
'IA': [1, 2, 3, 4, 5],
'age': [15, 21, 33, 41, 54],
'gender': ['female', 'male', 'male', 'male', 'male'],
'salary': [5000, 3000, 3200, 1200, 4000],
'house': ['I,1', 'I,2', 'III,3', 'I,1', 'V,2']
}
other_df_dict = {
'ID': [1, 2, 3, 4, 5],
'weight': [22, 11, 23, 43, 12]
}Right Join:以右边DF为基准进行join,join后的表的行数与右边DF一致。
df = df.join(other_df.set_index('ID'), on=['IA'], how='right')
'''
IA age gender salary house weight
0.0 1 15.0 female 5000.0 I,1 22
1.0 2 21.0 male 3000.0 I,2 11
NaN 6 NaN NaN NaN NaN 23
'''
# 数据如下字典所示
df_dict = {
'IA': [1, 2, 3, 4, 5],
'age': [15, 21, 33, 41, 54],
'gender': ['female', 'male', 'male', 'male', 'male'],
'salary': [5000, 3000, 3200, 1200, 4000],
'house': ['I,1', 'I,2', 'III,3', 'I,1', 'V,2']
}
other_df_dict = {
'ID': [1, 2, 6],
'weight': [22, 11, 23]
}Inner Join:内连,取两张表索引的交集。
df = df.join(other_df.set_index('ID'), on=['IA'], how='inner')
'''
IA age gender salary house weight
0 1 15 female 5000 I,1 22
1 2 21 male 3000 I,2 11
'''
# 数据同Right JoinOuter Join:外连,取两张表索引的并集。
df = df.join(other_df.set_index('ID'), on=['IA'], how='outer')
'''
IA age gender salary house weight
0.0 1 15.0 female 5000.0 I,1 22.0
1.0 2 21.0 male 3000.0 I,2 11.0
2.0 3 33.0 male 3200.0 III,3 NaN
3.0 4 41.0 male 1200.0 I,1 NaN
4.0 5 54.0 male 4000.0 V,2 NaN
NaN 6 NaN NaN NaN NaN 23.0
'''
# 数据同Right JoinLeft Join in Merge:左连。结果与Left Join不同之处在于保留了用于匹配的另一张表的列。
# 通过left_on与right_on设置用于连接的key。通过how设定连接方式,如下为左连。若存在相同列名,可以设置一个suffixes元组进行后缀设置
df = pandas.merge(left=df, right=other_df, how='left', left_on='IA', right_on='ID', suffixes=('_l', '_r'))
'''
IA age gender salary house_l ID weight house_r
0 1 15 female 5000 I,1 1.0 22.0 a
1 2 21 male 3000 I,2 2.0 11.0 b
2 3 33 male 3200 III,3 NaN NaN NaN
3 4 41 male 1200 I,1 NaN NaN NaN
4 5 54 male 4000 V,2 NaN NaN NaN
'''
# 数据如下
df_dict = {
'IA': [1, 2, 3, 4, 5],
'age': [15, 21, 33, 41, 54],
'gender': ['female', 'male', 'male', 'male', 'male'],
'salary': [5000, 3000, 3200, 1200, 4000],
'house': ['I,1', 'I,2', 'III,3', 'I,1', 'V,2']
}
other_df_dict = {
'ID': [1, 2, 6],
'weight': [22, 11, 23],
'house': ['a', 'b', 'c']
}
Right Join in Merge:右连。同上,不再赘述。
Inner Join in Merge:内连。取两列key的交集。与Inner Join不同之处在于保留用于匹配的另一张表的列。
df = pandas.merge(left=df, right=other_df, how='inner', left_on='IA', right_on='ID', suffixes=('_l', '_r'))
'''
IA age gender salary house_l ID weight house_r
0 1 15 female 5000 I,1 1 22 a
1 2 21 male 3000 I,2 2 11 b
'''
# 数据同上
Outer Join in Merge:外连。同上,不再赘述。
值得注意的是,设置left_index=True的意思为左表的key为其索引。left_index=与left_on=不得同时出现。
当两张表存在同名列时,可以使用on=进行指定:
# 连接后同名列将变为一列
df = pandas.merge(left=df, right=other_df, on='ID', how='left', suffixes=('_l', '_r'))
# 也可以按照多个同名列进行连接。可以传列表。默认为找两个DF内同名列。传列表时若这些列表存在多个相同的值,则会匹配多次,多增加几行,参考下面的结果。
df = pandas.merge(left=df, right=other_df, on=['ID', 'age'], how='left', suffixes=('_l', '_r'))
'''
ID age gender salary house_l weight house_r
0 1 15 female 5000 I,1 22.0 a
1 1 15 female 5000 I,1 11.0 b
2 2 21 male 3000 I,2 NaN NaN
3 3 33 male 3200 III,3 NaN NaN
4 4 41 male 1200 I,1 NaN NaN
5 5 54 male 4000 V,2 NaN NaN
'''
# 定义数据
df_dict = {
'ID': [1, 2, 3, 4, 5],
'age': [15, 21, 33, 41, 54],
'gender': ['female', 'male', 'male', 'male', 'male'],
'salary': [5000, 3000, 3200, 1200, 4000],
'house': ['I,1', 'I,2', 'III,3', 'I,1', 'V,2']
}
other_df_dict = {
'ID': [1, 1, 6],
'age': [15, 15, 35],
'weight': [22, 11, 23],
'house': ['a', 'b', 'c']
}若想知道连接用的key在两个DF中是否存在,则可以指定indicator=True,或indicator=’field_name’
df = pandas.merge(left=df, right=other_df, on=['ID', 'age'], how='left', suffixes=('_l', '_r'), indicator='ind_field')
'''
ID age gender salary house_l weight house_r ind_field
0 1 15 female 5000 I,1 22.0 a both
1 2 21 male 3000 I,2 NaN NaN left_only
2 3 33 male 3200 III,3 NaN NaN left_only
3 4 41 male 1200 I,1 NaN NaN left_only
4 5 54 male 4000 V,2 NaN NaN left_only
'''长表格转宽表格
用到 .pivot() 函数。
宽表格转长表格
用到 .wide_to_long() 函数。
# 全局设定
设置dataframe的小数点位数
pandas.set_option('display.precision', 10)
# 调试错误
调用 xgboost 时出现有关数据类型的错误,此处数据均为数字,因此使用 .to_numeric() 将每一列转换为数字类型。
# DtypeWarning: Columns (x,x,x) have mixed types. Specify dtype option on import or set low_memory=False.
data_df = pandas.read_csv('./abab.csv', usecols=[1, 2, 3, 4, 5, 6])
for cname in data_df.columns:
data_df[cname] = pandas.to_numeric(data_df[cname], errors='coerce')# 检查每行是否包含0值
检查每行是否有元素为0,并将包含0值的行剔除。其中 .all(axis=1) 是返回是否每一个元素都符合条件的方法。
df = df[(df != 0).all(axis=1)]
# 缺失值处理
有多种方法处理缺失值,其中典型方法是插值和删除。
将缺失值转为平均值:
也可以将 NaN 视为一个类别值或离散值:
data_col = pandas.get_dummies(data_col, dummy_na=True)