训练模型之后应该做的事。
# 序
上一则帖子带来了深度学习的基础知识用于入门,该帖子谈一谈模型拟合后应该做哪些事。具体而言,流程如下:
- (训练前后均可)模型选择:多项式次数、正则化系数、神经网络架构等均可通过 Jcv 来选择。训练后若模型表现欠佳,也可以通过该步骤调整模型细节。
- 模型评估:回归与分类模型选用不同指标
- 根据评估指标 Jtrain 与 Jcv 等判断模型的表现——高偏差 High Bias 、高方差 High Variance 还是刚刚好?
- 结合模型的表现,再根据基准与学习曲线确定改进模型的手段
总的来说,首先通过对比 Jtrain 与基准判断模型是否高偏差; 然后通过对比 Jtrain 与 Jcv 判断模型是否高方差; 然后通过观察学习曲线判断是否需要增加数据量来改善效果; 最后结合上面的发现,选取合适的方法改善模型表现。
# 调试
如在一个正则化线性回归中得到预料之外的巨大误差,那么可以尝试以下方法:
- 投喂更多训练样本 High Variance
- 尝试更少的特征 High Variance
- 尝试加入额外的特征 High Bias
- 尝试加入高次项(x12, x22, x1x2, etc) High Bias
- 尝试减小正则化系数λ High Bias
- 尝试增加正则化系数λ High Variance
# 模型诊断
诊断是用于发现为什么模型无法很好运作的测试,旨在为提升模型表现提供指导。
模型评估
当训练出一个模型,它拟合、泛化的性能是最受关注的地方。如果数据集仅含两个或三个特征,可以通过绘制图的方式查看拟合、泛化的效果。然而事实上往往会有更多特征,因此需要另一种方法来评估模型。
推荐的方法是将数据集按照 7:3 或 8:2 拆分为训练集和测试集。下图展示了训练集与测试集的样本标号:
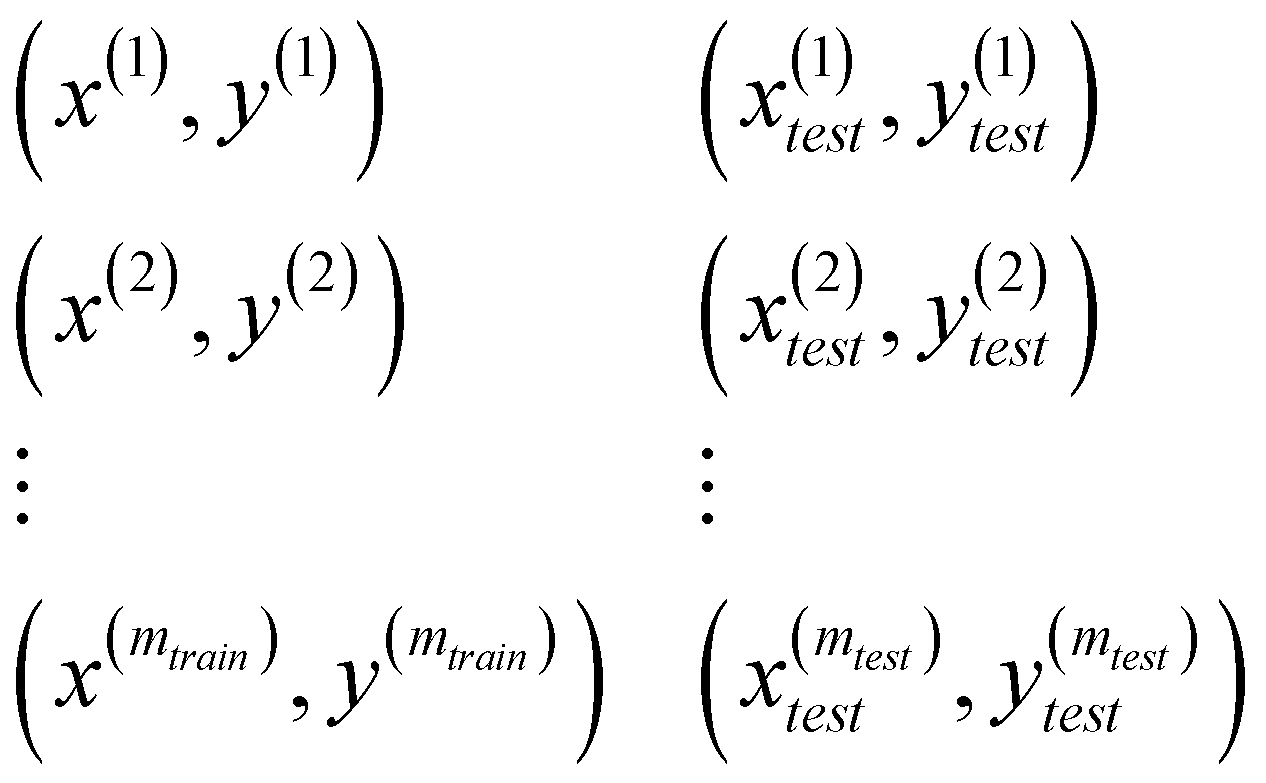
回归模型的评估:在拟合的过程中,将每一次迭代计算出的参数用于计算损失,之后用于绘制学习曲线以评估模型。下图中第一个带正则化项的公式用于拟合参数时最小化损失; 第二个公式结合每次迭代的参数计算训练集的损失; 第三个公式结合每次迭代的参数计算测试集的损失。可以发现后两者计算训练集和测试集的损失时均不带正则化项。

0/1分类模型的评估:用于分类模型评估的算法有两种,第一种和回归模型一致,计算训练集和测试集的损失以评估模型;
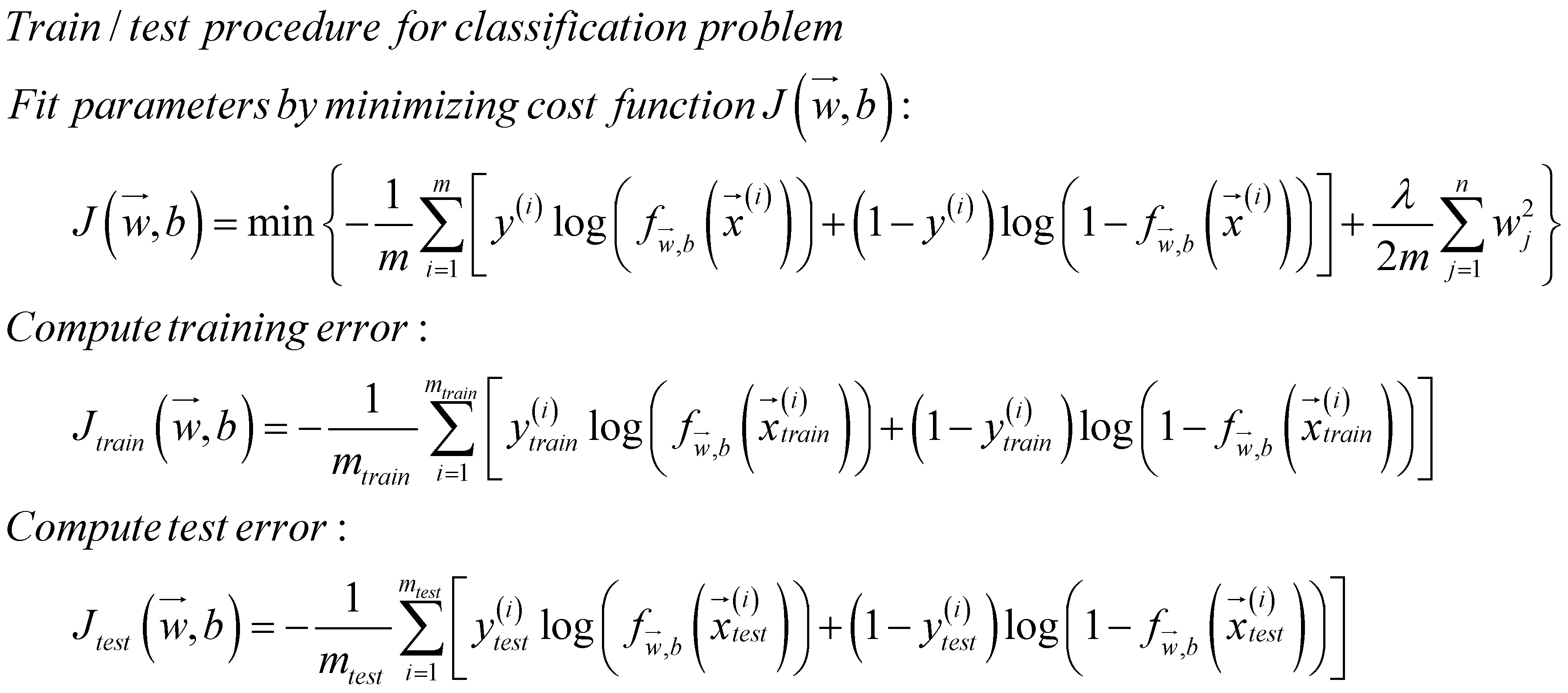
第二种运用得更广泛,即计算训练集与测试集中模型输出错误结果的占比。

交叉验证集
模型架构选择
上文提到,可以使用 Jtest 来观察模型的性能。然而在实践中,往往还需要进行模型选择—神经网络架构、多次项的次数等等。若不引入交叉验证集 Jcv 则很容易高估模型的泛化性能,因为两笔数据既要当守门员又要当裁判。
因此,按照 6:2:2 的比例划分数据集为训练集、交叉验证集和测试集,使用前两笔数据选择损失最小的模型或架构,再使用最后的测试集来测试模型的泛化性能。交叉验证集标号如下:
通过下述公式计算每笔数据的损失:
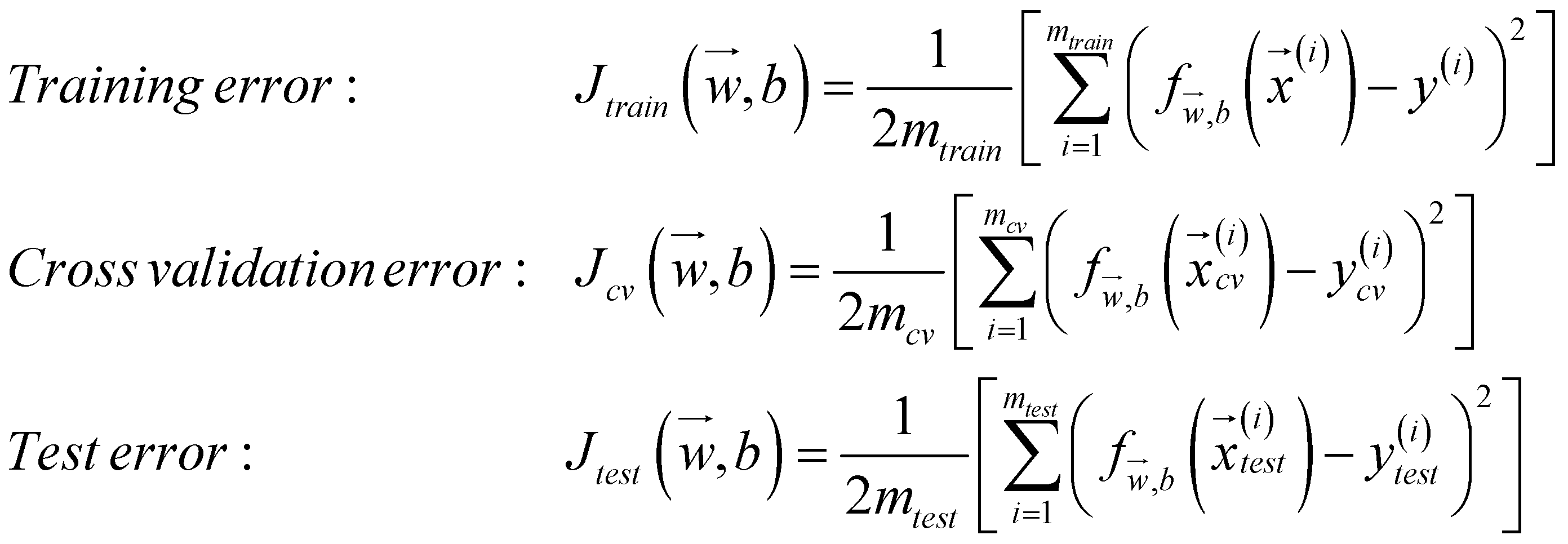
可以发现,三个式子均不带正则化项,因为这是在计算三笔数据的损失,而不是最小化损失。
模型表现
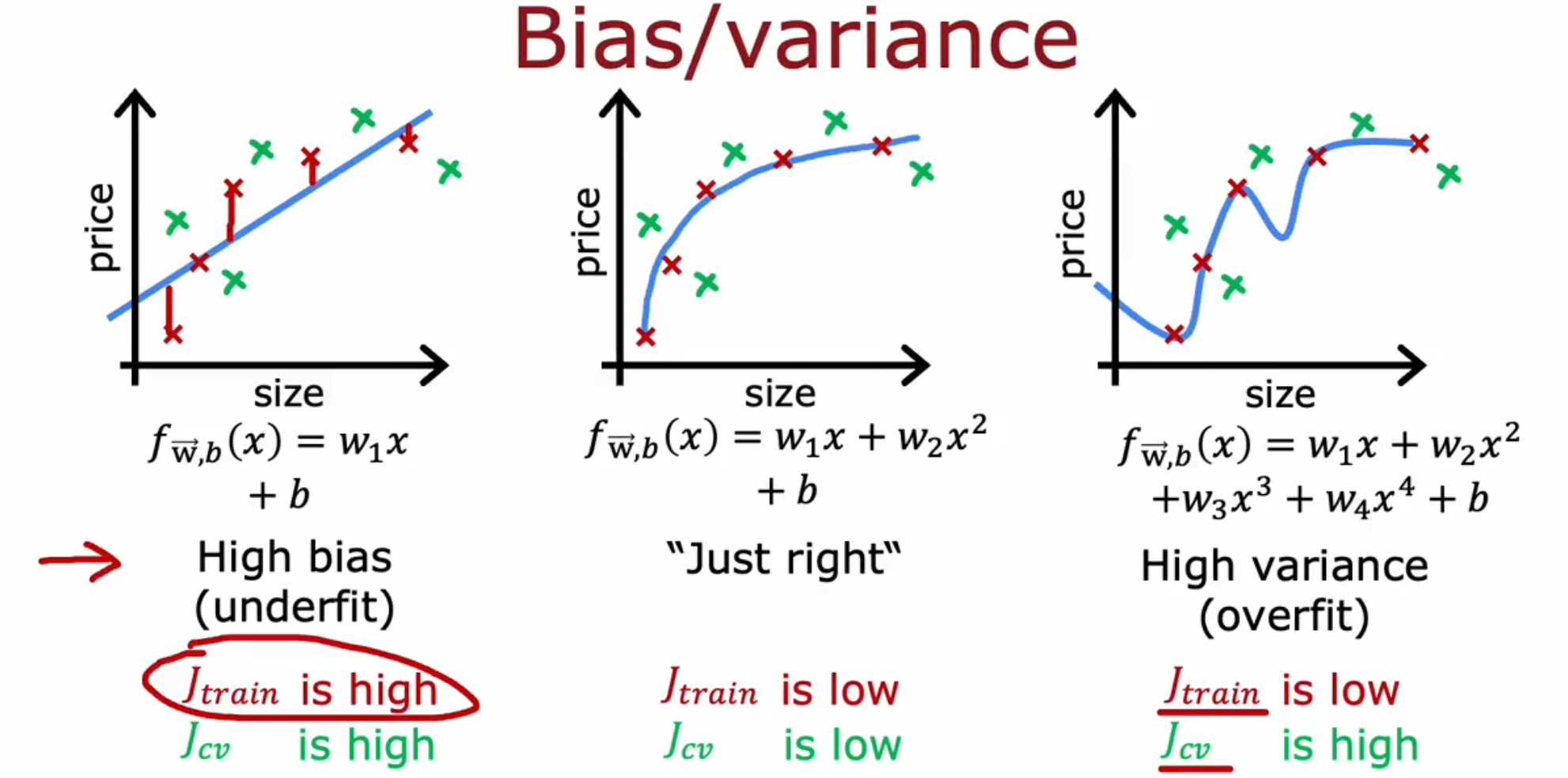
通过模型拟合数据后,模型有三种表现:
- 欠拟合,高偏差 High Bias :指标 Jtain 和 Jcv 的值都很高(较基准而言)。
- 刚刚好:指标 Jtain 和 Jcv 的值都很低(较基准而言)。
- 过拟合,高方差 High Variance :指标 Jtain 的值很低,指标 Jcv 的值很高(较 Jtain 而言)。
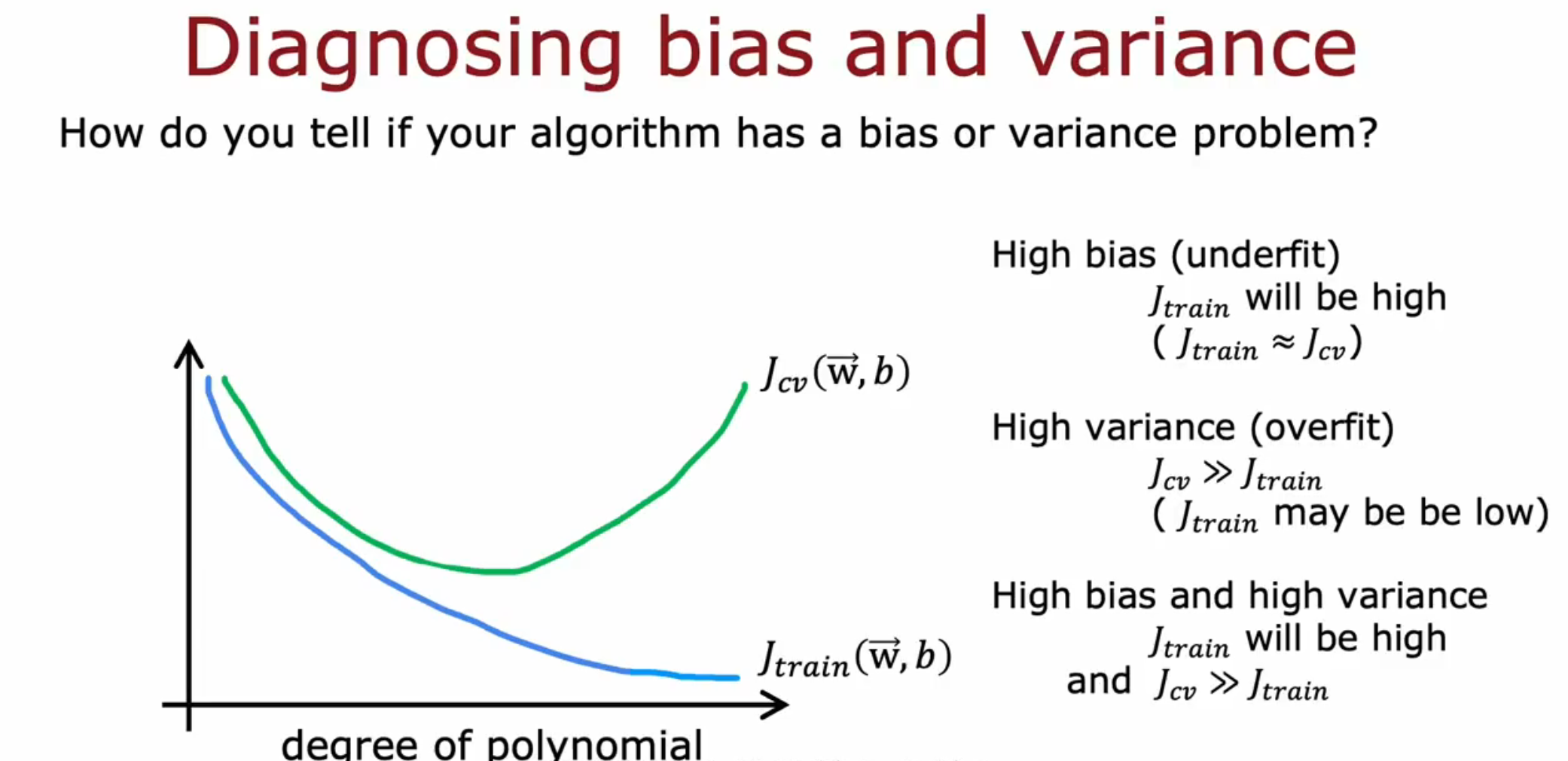
在模型的多项式高次项次数选择和正则化系数选择时, Jtain 和 Jcv 如下图所示随次数、正则化项大小变化而变化。
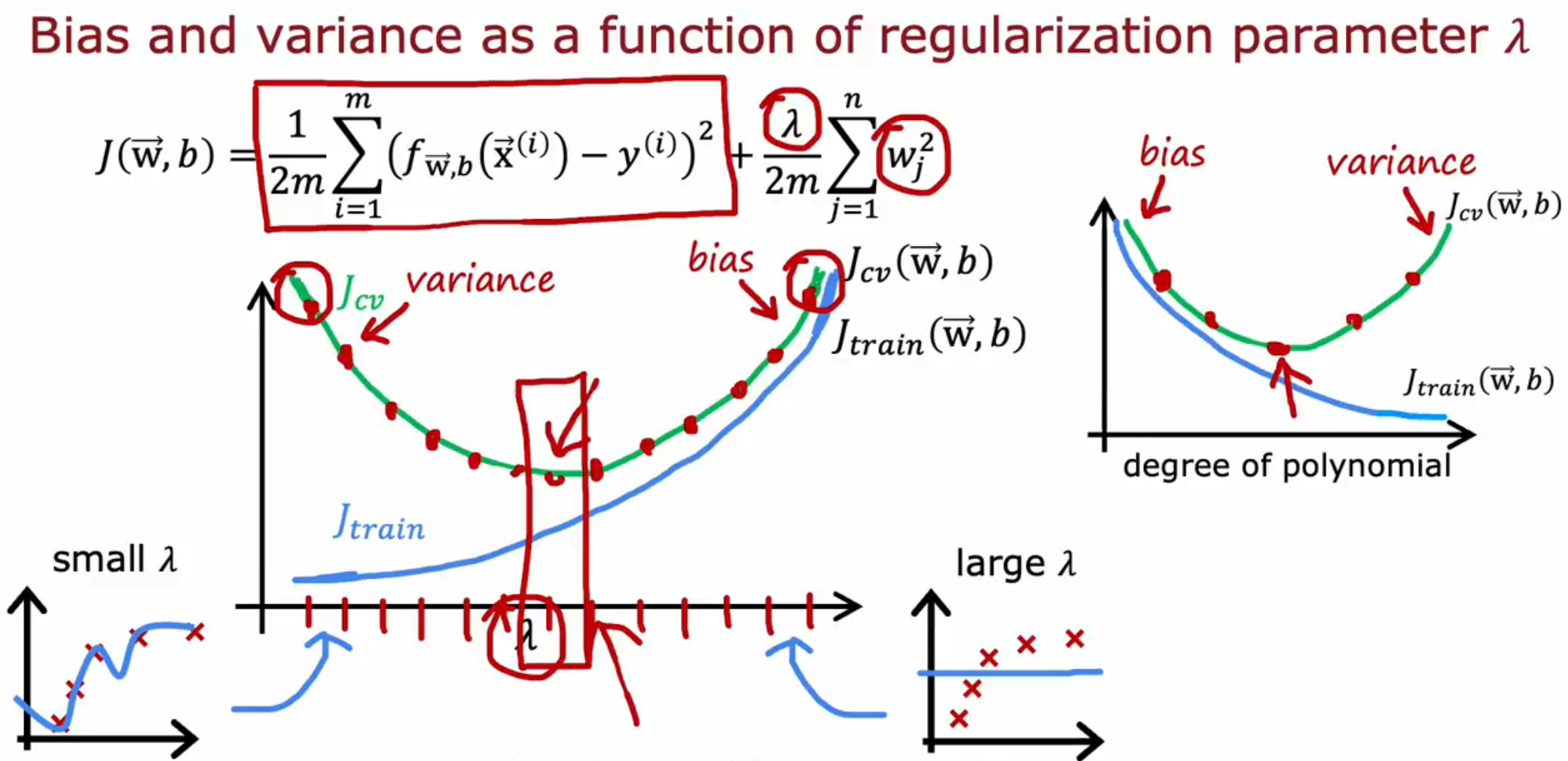
当 λ=0 时,正则化项系数为〇,进而使得正则化无效并且可能造成 High Variance ; 当 λ→∞ 时,正则化项会将函数惩罚至一条直线,进而造成 High Bias 。因此需要选取合适的 λ 使得模型表现得最佳,可以尝试0,0.01,0.02,0.04,0.08…10,绘制 Jtain 和 Jcv 与 λ 的函数曲线或直接选取使两个损失值最小的 λ 。
# 评估基准
通过 Jtain 和 Jcv 等指标判断模型表现的好坏时,有必要明确一些基准。
基准:
1.人类在该领域的表现水平
2.最新已发表论文或竞争公司的算法的表现水平
3.根据经验或目标
如在音频分类实践中(下图),判断 Jtain 的好坏可以通过将它与人类在音频判断的准确率相比。若人类错判率为10.6%,而 Jtain=10.8% ,那么该模型表现得不错。进而观察验证集损失,若 Jcv=14.8% 明显较训练集损失大则说明模型表现为高方差、过拟合 High Variance 。

若 Jtain=15.0% 较基准大很多,但与 Jcv 相差不大,则该模型表现为高偏差、欠拟合 High Bias 。

若 Jtain=15.0% 较基准大很多,并且 Jcv=19.7% 也较训练集损失大很多,则该模型表现为高偏差、高方差,既欠拟合又过拟合(在神经网络中偶尔遇到该情况)。

# 学习曲线
学习曲线旨在帮助用户了解模型的表现如何随所拥有的经验量(如数据量)变化而变化。通过观察学习曲线用户将了解模型的表现并且得知是否应该增加数据量。
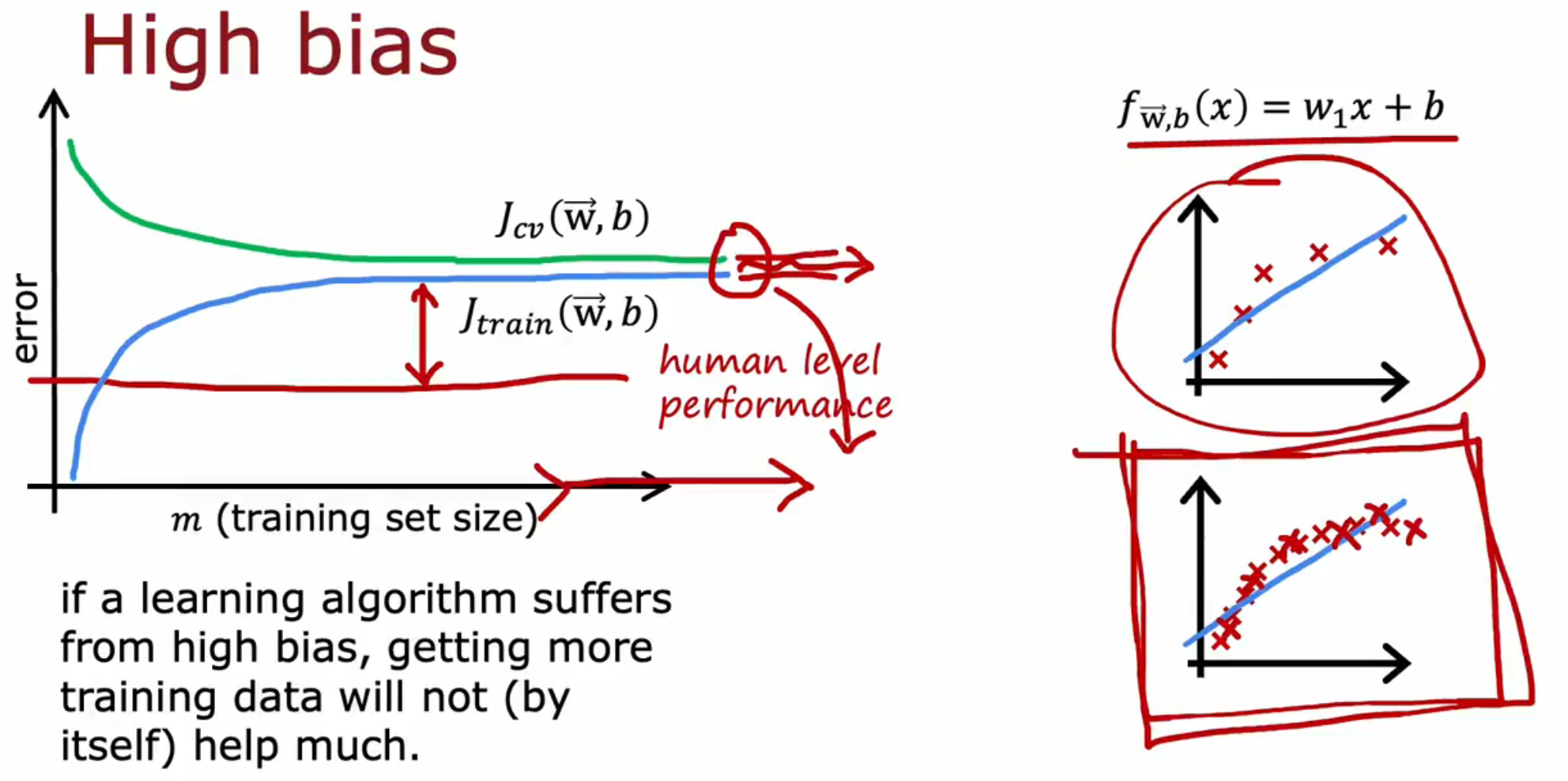
如下面的学习曲线描绘出一个模型表现为高偏差,这时 Jtain 和 Jcv 都高于基准,并且右侧趋向于水平线。这时仅增加数据量对模型表现并无正面影响。此时应考虑加入高次项、减小 λ 与添加额外特征。
下面的学习曲线描绘的是一个模型表现为高方差,这时 Jtain 低于基准而 Jcv 高于基准,并且可以看出二者的曲线还远未到趋于水平的地步。这时应考虑增加数据量、降低高次项的次数、减少特征数量、增加 λ 。
