麻了,之前学了一遍跟没学一样。
# 序
什么是科学?百科上显示科学是一种系统性的知识体系,它积累、组织并可检验有关于一切事物的解释和预测。而统计学则为这个量化的过程提供科学方法的理论体系。统计学是一门获取、分析数据的方法,为设计、描述和推断提供方法学基础。
设计是对数据收集方法的计划,考虑如何抽取访谈对象、抽取多少访谈对象、使用电话还是怎样、怎样设计问卷等。
描述是对现有数据的总结和提炼。因为很多信息是无序的,我们要找到特点去简化它,然后提炼信息。
推断是依据样本对总体进行推测。研究者通常感兴趣的不是样本本身,而是总体。所以对总体进行抽样,得到样本后进行分析,进行描述性统计,进行统计建模。但得到的是样本的特征,所以要从样本的特征推断总体的特征。统计推断为基于样本进行的可靠性推测提供了科学的方法。
描述和推断是两种最基本的统计分析类型,研究者通常结合这两种方法试图对各种社会现象进行探究。
统计学这一个个参数,是相互补充的。就像平均数描述不到的,方差来描述一样。很多参数都是拿来补充的。
推荐几本书:mathematical statistics with application(让老师醍醐灌顶)、statistical inference(概率论数理统计,要求较高的数学能力)、Statistical Methods for the Social Sciences(课程里很多例子用的这本书)
# 社会调查数据库

# 基本概念
研究对象:研究所观测的个体
总体 :研究所感兴趣的所有对象的集合
样本:研究所收集到的属于总体子集的数据
参数:对某一总体特征的数量概括,可以是总体的平均值、方差、四分位数等。
统计量:对某一样本的特征的数量概括
简单随机抽样:简单随机抽样也称为单纯随机抽样、纯随机抽样、SRS抽样 ,是指从总体N个单位中任意抽取n个单位作为样本,使每个可能的样本被抽中的概率相等的一种抽样方式
抽样框:抽样框又称“抽样框架”、“抽样结构”,是指对可以选择作为样本的总体单位列出名册或排序编号,以确定总体的抽样范围和结构。设计出了抽样框后,便可采用抽签的方式或按照随机数表来抽选必要的单位数。若没有抽样框,则不能计算样本单位的概率,从而也就无法进行概率选样。
数据收集方式:抽样调查、实验研究、观察性研究
# 变量
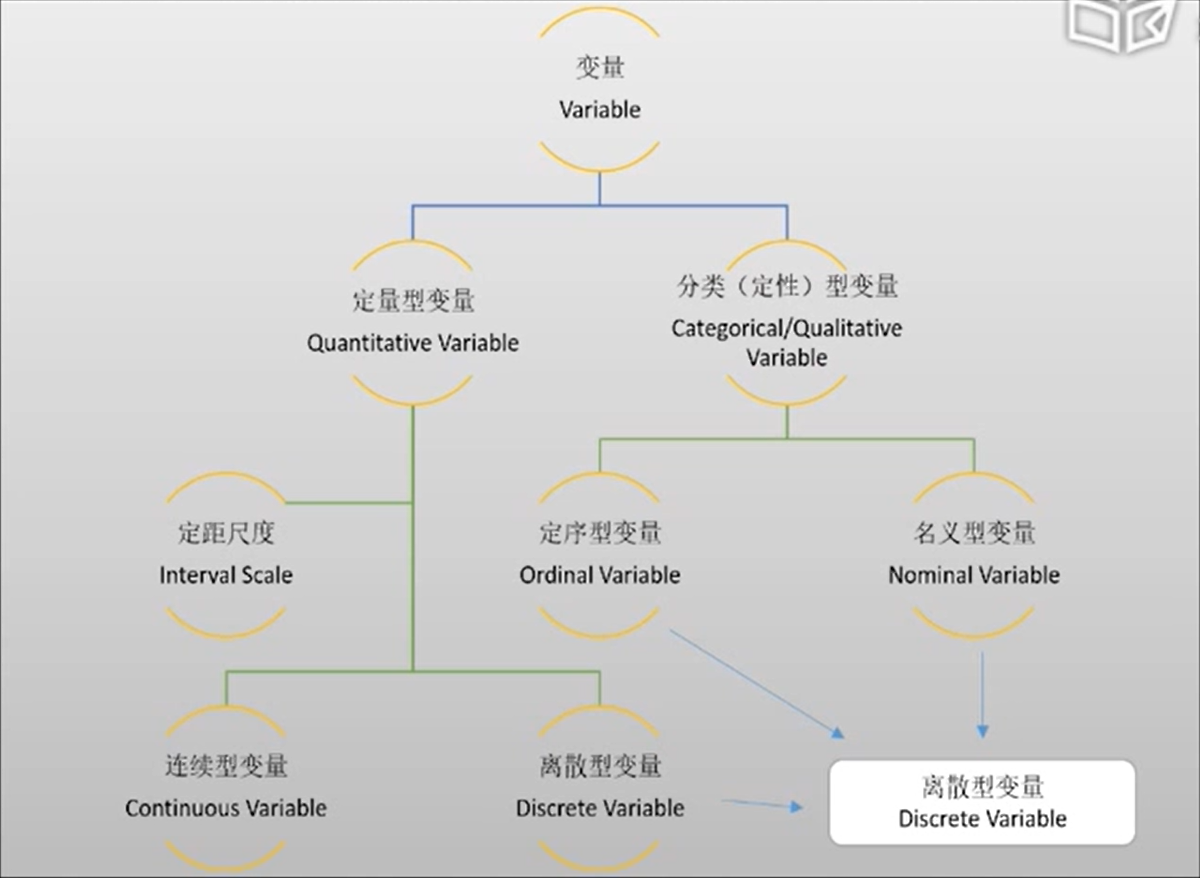
在绘图的时候,对于定量型变量,图中需要反应数据的集中趋势、离散程度、形状(对称分布、左偏分布、右偏分布),以及数据有没有突然的聚集、有没有gap,有没有异常值。
分类变量:
- 名义变量:民族、性别等
- 定序变量:对事情的看法(非常同意、同意、不同意、非常不同意)
- 连续型变量重新分组后的组别:年龄组、收入组等
离散程度的测量:
离散程度测量观测数据之间的差异程度。最常用的离散程度测量值包括极差、四分位差、标准差。
集中程度的测量:
描述数据的中心在什么地方。最常用的有均值、中位数、众数、算术均值。
# 探索性数据分析
EDA概念与目的:
EDA是指通过分析数据来总结数据主要特征的方法,分析手段包括作图、制表、计算数值特征,可视化是其鲜明的特征。整个过程不一定需要统计建模,主要目的还是在尽量少的先验假设下让数据告诉我们答案。
EDA的目的包括:
- 鉴别变量之间有趣的或是意想不到的关系
- 检视是否有支持或反对某项假设的证据
- 检查数据收集是否存在问题,比如缺失值和测量误差
- 识别可能需要收集更多数据的领域
EDA制图原则:
相对比较:
如果实验证明A假设更为正确,那么一定会有一个B假设与之对应。这就涉及到零假设和备择假设了,总之作图一定要体现出来。
如下图所示,很明显右侧的图加上了控制组,体现出了比较。而左侧的图就没有体现出比较。

体现因果、机制、解释和系统结构:
展示思考问题时的因果推理框架,因为即使通过精密的设计收集获得的数据,证明一件事导致另一件事的原因都是非常困难的。但通过数据图形的手段展示寻找原因的思考过程通常是有价值的。这种展示可能支持或否定某个假设,更重要是,它们会提出值得展开新一轮数据收集与分析以追踪新的问题。
如这个儿童哮喘和空气净化机的问题。加了空气净化机之后哮喘儿童的症状日减少了。那背后的假设是空气净化机净化了空气重颗粒物,那么再补一个空气中悬浮颗粒物浓度的箱线图,就更好了。但即使是这样,也没办法说明加入空气净化机就是导致哮喘儿童无症状增加的原因。因为有太多太多混淆变量了。
展现多元数据:
现实世界是多元的,对于研究的问题都可能有很多可能测量的特征属性。
比如科学家收集数据发现,PM10浓度也高死亡率越低,这明显和尝试相悖。所以思考什么会影响死亡率,季节是一个因素。所以将收集的数据按季节分类,发现PM10浓度越高死亡率越高。
内容:
内容至上,一张图在没有人讲解的情况下,自身能说明一个完整的故事。
# 使用R出图
柱状图与饼图:
生成频数使用 table() 函数。查看频率则使用 prop.table() 函数。
counts <- table(mtcars$gear) //会赋值给counts,缸数对应的汽车数量,也就是频数
gear.freq <- prop.table(counts) //获得频率
gear.freq
输出:
3 4 5
0.46875 0.37500 0.15625
为了画饼图,创建以下数据
slices <- c(30,70)
lbls <- c("UK", "US") //这个是为了让图更有意义,解释在画什么数据已经获得了,那么可以进行出图了。
barplot(counts, main = "Car Gear Distribution", xlab = "Car Gear") //根据EDA制图的内容至上原则,制的图需要有主题、X轴、Y轴等说明
pie(x = slices, labels = lbls) //画饼图,这个slices不一定是百分数数据,可以是频数数据,该画图函数会自动计算占比。点图、茎叶图:
使用BHH2包的 dotPlot() 函数绘制点图。
使用 stem() 函数绘制茎叶图。
dotPlot(mtcars$gear, xlab = "Gears of Cars", main = "Gears Distribution") //点图。
stem(mtcars$gear) //茎叶图,会直接在控制台输出。不会输出图片。
直方图:
使用 hist() 函数绘制直方图。
hist(mtcars$gear, main = "Histogram of Gears", xlab = "Gears of Cars", col = c("red", "blue")) //生成直方图,使用col来设置颜色。箱线图:
如果箱线图最左侧为数据的最小值,那么左边的端点就是真实的最小值。真实的Lower Bound和Upper Bound计算是:
Lower Bound = Q1 - 1.5IQR
Upper Bound = Q3 + 1.5IQR
IQR是四分位差箱线图可以清楚看到异常值。使用 boxplot() 函数来绘制。
boxplot(x = mtcars$mpg) //使用该函数,离群值会被以圆点的形式标出来# Logit回归模型
使用ISLR包的Default数据集。使用stats包的 glm() 函数进行Logit回归分析。使用 predict() 函数来预测y的值,在绘制这条Logit回归曲线的时候,实际上是绘制从x1到x2对应的y的值并将它们连起来(尽量多,多的话才像曲线,少的画连起来会有很明显的拐点)。然后使用 lines() 绘制到高级图像上。
logfit <- glm(default ~ balance, data = Default, family = binomial(link = "logit"))
df2 <- data.frame(balance = seq(min(Default$balance), max(Default$balance), len = 10000)) //新建一个数据框,列名一定要是进行Logit回归分析使用的列名,这是predict()函数要求的。不一定是从最小值到最大值,可以是任何一个区间,但len一定要大,才能像曲线。
df2$pred <- predict(logfit, df2, type = "response") //使用predict()函数进行预测,它会使用输入的logfit模型在新输入的数据框中寻找对应的列。type使用response,这是帮助文档写的。
lines(y1 ~ x1, data = df2, col = c("blue")) //绘图# 概率
- P(not A) = P(Ā) = 1 – P(A)
- P(A or B) = P(A ∪ B) = P(A) + P(B) – P(A ∩ B) 如果AB为互斥事件,则不用减A交B了。
- P(A and B) = P(A ∩ B) = P(A) * P(B|A) AB同时发生的概率为A发生的概率乘以A发生的前提下B发生的概率
- P(B|A) = P(A ∩ B)/P(A)
- P(B|A) = P(B) 如果事件A与B无关,那么A发生的情况下B发生的概率还是P(B)
- P(A ∩ B) = P(A) * P(B) 如果两事件独立,则A交B的概率等于A的概率乘B的概率,这是两事件独立的充要条件
注意,互斥的意思是A发生B肯定不发生,则A对B是有影响的那么就不独立了。互斥不是独立,事实上,两事件互斥,则必不可能独立。
离散型随机变量概率分布与连续型随机变量概率分布:
只能取到有限个值的变量称为离散型随机变量,取到的值不能一一列举只能用数轴的一个区间表示的变量称为连续型随机变量。
离散型随机变量的概率分布:
离散型随机变量的概率分布是一个包含了随机变量所有可能取值以及它们所对应概率的表格、列表或公式。取到这些值的概率之和应该为1。
可以使用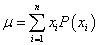 来计算离散型随机变量的均值,使用
来计算离散型随机变量的均值,使用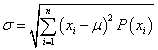 来计算离散型随机变量的方差。
来计算离散型随机变量的方差。
连续型随机变量的概率分布:
连续型随机变量的概率分布是一个包含了变量所有可能取值以及它们所对应概率的图示或函数。这个函数通常称为连续型随机变量的概率密度函数,简称密度函数。
实际上连续型随机变量的概率分布关注的是变量落入某一区间的概,变量落入任意特定区间的概率在0~1之间。那么连续型随机变量概率分布的图示可以由一条平滑曲线来表示,曲线下的面积则表示落入该区间的概率。所以连续型随机变量的概率一定是以面积作为测量基础的。如f(x=4)表示的是x=4时发生的概率,而这个概率应该是0.而整个密度函数下面积为1.如果要求变量落入1到2之间的概率,则应该对这条函数求下限为1上限为2的积分。
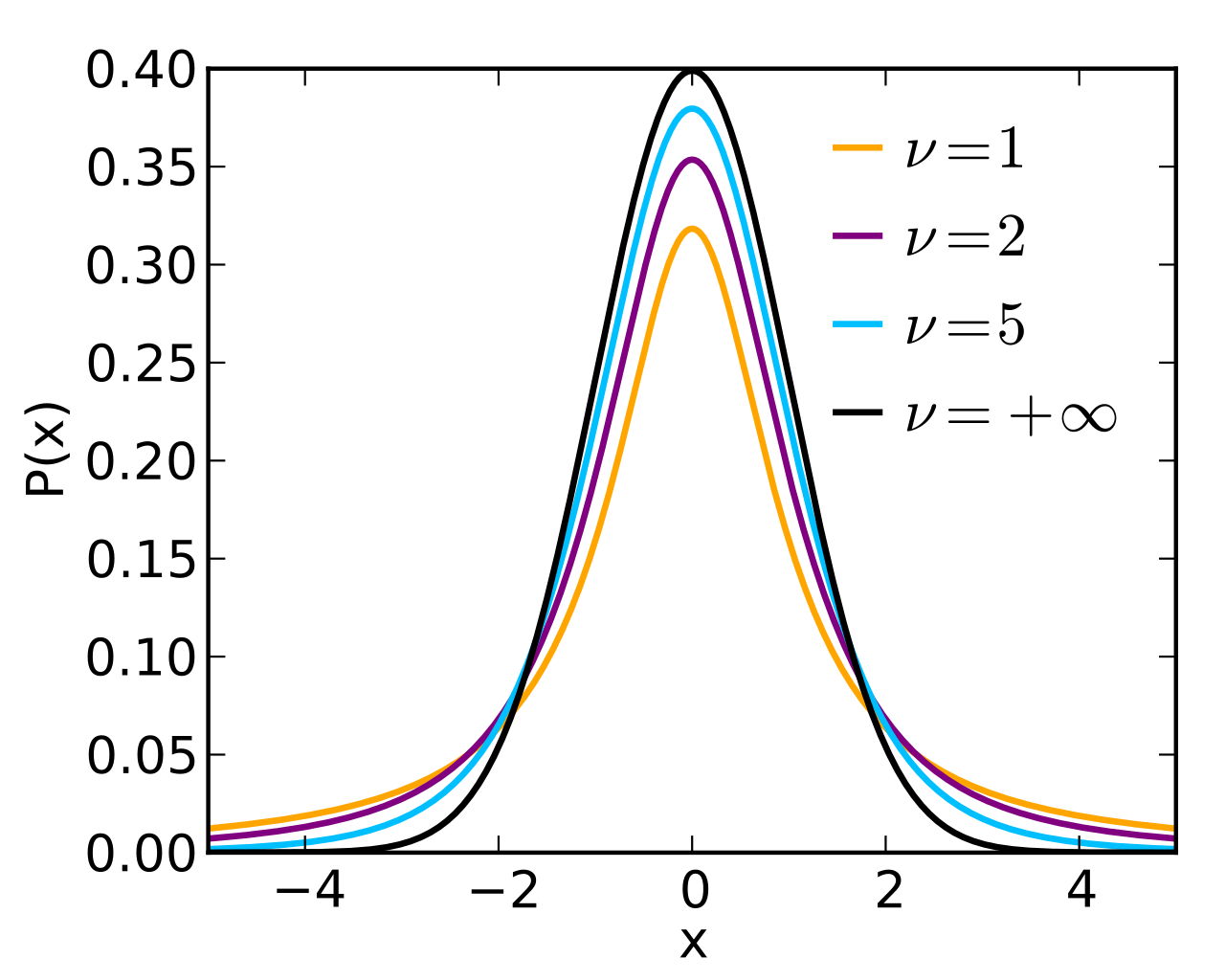
# 正态分布
正态分布也叫高斯分布,在统计推断中发挥举足轻重作用。正态分布形态由均值μ和标准差σ决定。X~N( μ ,σ),正态分布密度函数为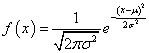 ,真实世界很多变量都高度近似正态分布。如果一个变量本身服从一个均值为 μ 标准差为 σ 的正态分布,则标准化之后会服从均值为0标准差为1的正态分布了。
,真实世界很多变量都高度近似正态分布。如果一个变量本身服从一个均值为 μ 标准差为 σ 的正态分布,则标准化之后会服从均值为0标准差为1的正态分布了。
# 抽样分布
比如调查某候选人的支持率(假设支持与否是55开),从700万个人中随机抽取2705个投票人,得出该候选人支持率为57.5%,接下来我们要计算的是在支持与否55开的情况下抽2705个人得出57.5%这个数字奇怪不奇怪。生成350万个0和350万个1,当进行了1000次样本容量为2705的随机抽样后,发现没有一次支持率大于57.5%,说明57.5%这个数字是很奇怪的,候选州长的概率大于55开。
但实际抽样中,我们根本不可能重复抽取1000次,很可能就进行一次抽样。所以后面引用到置信区间这个概念后会更科学的判断,不过这就属于理论分布了。
在实际研究中,计算样本的均值是为了预测总体均值。但当我们实际计算出样本均值之后,不知道这个样本均值离总体均值多远。所以可以通过研究这个样本均值的离散程度来预测该样本的准确程度。也就是说希望知道这个抽样分布的均值和标准差。
想象一下这个过程:
- 一个均值为μ的总体
- 从这个总体中随机抽取一个样本量为n的样本,该样本的均值为x̄。希望用x̄来估计μ
- 不同的随机样本会导致不同的x̄的取值,于是我们认为x̄是一个随机变量
- 实际上,样本均值x̄围绕着总体的真实值μ波动,每一种x̄的取值都已某种概率出现。有些值相比于另一些值,出现的概率会高得多。
那么,均值的均值(不同样本的x̄的均值),就等于总体的真实值。可以证明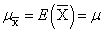 以及
以及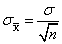 ,后面这个式子计算的是样本均值抽样分布的标准误,描述了抽样分布中样本均值的标准差。标准误描述了不同样本中样本均值的取值有多么不同。
,后面这个式子计算的是样本均值抽样分布的标准误,描述了抽样分布中样本均值的标准差。标准误描述了不同样本中样本均值的取值有多么不同。
补充一点,标准误本身就是标准差,这个表达只是用在抽样分布时的固定表达,区别前面所说的总体中各观测值的离散程度。
极限中心定理:
中心极限定理。在适当的条件下,大量相互独立随机变量的均值经适当标准化后依分布收敛于标准正态分布。这组定理是数理统计学和误差分析的理论基础,指出了大量随机变量之和近似服从正态分布的条件。
对于一个样本量足够大的随机抽样,样本均值x̄的抽样分布近似服从一个正态分布。也就是说,不管总体是服从什么分布的,可能是特别偏的分布可能是无比离散的分布,但它的样本均值的分布一定是服从正态分布的。
那么这个样本量足够大是多大呢?这和总体偏斜程度有关,越偏要求样本量越大,那么一般情况下样本量为30以上就够让抽样分布近似正态了。
有了这个定理我们就知道了各种分布它样本均值的分布了,近似正态分布。那么可以借助正态分布的性质,帮助我们了解样本均值不同取值发生的概率大小。再应用经验法则,我们就能知道样本均值极有可能落在与总体均值相距三倍标准误的范围内,也就是均值左右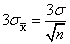 这个范围内。
这个范围内。
# 点估计和区间估计
点估计是作为参数最好猜测的那个值。区间估计是被认为包含总体参数的、围绕着点估计的一个区间。
参数的点估计:
任何一个参数都有很多种可能的估计量,对于一个正太分布来说,如果想用一个估计量来估计分布的中心,可以选择均值、中位数、甚至是众数。
一个好的估计量,它的抽样分布应该满足两个条件:
- 无偏性:应该以真实的参数值为中心分布
- 有效性:标准误越小越好
什么是无偏呢,比如用样本的均值的均值来估计总体的均值,就是无偏。但用样本极差估计总体的极差,显然是有偏的。
什么是有效性呢,比如E(1/2X1+1/2X2)的均值还是μ,但标准差就是σ/√2,除非n=2,否则得到的标准差都会比之前的σ/√n大。
估计的极大似然法:
Fisher认为,极大似然估计值应该是与观测数据最为一致的一种估计值,所谓一致,是指如果总体参数等于这个估计值,那么我们得到手头的、眼前的这组观察数据的概率应该是最大的,它应该大于当总体参数等于其他任何数值时得到这组观察值的概率。
比如得到1的概率比得到其他任何观测值的概率都大,那么1就是极大似然估计值。
在正态分布里面,样本均值就是总体均值的极大似然估计值。
参数的区间估计:
置信区间:一个参数的置信区间是我们相信这个参数会落入的一个数值区间。这种方法产生的一个区间,它包含参数真实值的概率被称为置信水平。代表置信水平的数值通常都接近于1,比如0.95或0.99,因为我们需要这个概率足够大。
置信区间的构建:
- 抽样分布一般都近似的服从正态分布,正态分布可以进而决定估计值落入某参数一段距离内的概率究竟是多少。
- 置信水平95% —> 估计值会落入距离真实值两个标准误的范围内
- 我们几乎可以确定估计值会落入距离真实值3个标准差的范围内
置信区间的形式:点估计±边际误差。
边际误差是标准误的倍数,具体是标准误的几倍,要根据置信水平的大小决定。
在R中,使用 qnorm() 代码来查看Z2/σ的取值。如 qnorm(0.05/2) 就是查看95%置信水平Z2/σ的取值。
总体比例的置信区间:
在分类变量中,每个分类中至少有15个观测值,才能拿来构建样本比例置信区间。如非常同意到非常不同意,每一种选择都需要15个以上的人去选择。如果不满足这个条件,就不能使用参数的方法去构建置信区间了,而要使用非参数的方法。

总体均值的置信区间:
同总体比例的置信区间完全一致,均值的置信区间也采取如下形式,即 点估计 ± 边际误差。边际误差仍然是标准误的某种倍数,总体均值μ的点估计是x̄。
对于一个样本量足够大的随机样本,根据极限中心定理,我们知道样本均值x̄的抽样分布近似正太分布。所以对大样本来说,我们可以通过用来自于标准正态分布的某个标准计分z-score乘以标准误来求得边际误差。
样本均值的标准误为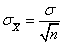
T分布:
如果样本量比较小,就不适用于之前的方法。而T分布对于任何样本量都可以用来求置信区间。
那么上一个方法为什么要求样本量足够大?是因为它想用极限中心定理。T分布不要求样本量大小,所以它有个条件,就是总体要服从正态分布。构建置信区间方法还是和之前一样,使用样本的标准差取代总体标准差。但有以下几个问题:
- 使用估计标准误,就不可避免引入额外的误差
- 当样本量相对较小时,这个额外的误差很可能是不能忽视的。
- 于是置信区间就要变宽,要用一个稍大一些的数代替z得分。这就是t得分,t-score。注意t score不是T统计量!
- t-score来自t分布,该分布和正态分布很像,只是离散程度稍大。
T分布的性质:
- 正态的、钟形的
- 它的标准差稍大于1(形状表现为胖尾巴,尾部稍微高一点)
- 它的形状仅有一个参数决定,叫做自由度(df),df=n-1
- 自由度增高,就表示样本量变大了,自由度越大它的尾巴就越来越瘦,直到和标准正态分布重叠。当自由度>30时,T分布形状与标准正态分布基本一致。
- 总体均值的置信区间中的边际误差是由t-score乘以估计标准误得到的。
# 统计推断
显著性检验:
很多研究都有共同的目的,就是检查手头获得的数据是不是和某种预期相吻合。显著性检验是通过对数据的分析总结关于假设的证据,它是通过比较从数据中获得的参数点估计和假设中所预测的参数取值来实现的。
显著性检验(significance test)也叫做假设检验(hypothesis test),简称检验(test),所有的检验都包含五个部分:
- 前提假定(assumptions)
- 假设
- 检验统计量
- P值
- 结论
假定:
假定和假设是有区别的,假定是对数据的一些前提条件才能保证检验是有效的。包括数据类型、随机化过程、总体分布
数据类型:不管是什么统计方法第一件事就是要把变量类型分清楚。分类变量看比例,数值变量看均值。
随机化过程:检验认为数据是遵循随机化的原则收集的。这样才能保证样本是有代表性的。
总体分布:对于一些检验,我们对总体的分布是有所要求的。和构建总体均值的置信区间类似,有些检验要求总体服从正态分布。这个是因为有时候样本量很小,所以要假定总体服从正态分布。但当样本量足够大,就可以使用中心极限定理了。
样本量:许多检验的效度随着样本量的增加而增加。
假设:
每个显著性检验都会有2个对于参数值的假设——原假设和备择假设。原假设是对总体参数等于某个特定取值的陈述。备择假设则认为参数会落入某个备选的取值范围。
通常,原假设体现的是一种没有影响的状态,是对原始状态的一种继承。而备择假设通常代表某种类型的效应产生了,代表了一种对原始状态的挑战。有时我们直接把备择假设称为研究假设,因为它恰恰是我们想要证明的那个陈述。
显著性检验分析由样本获得的针对原假设的证据。一定是冲着原假设来的,推翻也是推翻原假设,证明也是证明原假设。
检验最直接的目的:搜寻数据反对原假设的证据,如果成功找到了这个证据,就进而认为备择假设是正确的。这种方法实际上是利用了反证法的一种间接证明。研究人员通常通过假设检验来搜集支持某个备择假设的证据,所以备择假设常被称为研究假设,这些假设在数据收集和分析前就已经建立。
这很重要,我们建立的显著性检验(假设检验)一般从理论中来,有一个先验的理论才会有想法去收集数据做一个研究区证明它。
检验统计量:
在进行显著性检验的过程中使用的那个统计量,备择假设中所关注的那个参数一定会有一个点估计,从样本值会得到关于参数的点估计。而检验统计量就总结了这个点估计和原假设中的参数值相差多远。通常是通过点估计与假设值之间相差了多少个标准误的距离来表达的。
P值:
在通过检验统计量计算出样本点估计与原假设距离后,需要构造一个概率总结。也就是通过样本统计量的抽样分布,表达出在原假设为真的情况下,得到这个样本统计量的概率是多少,到底有多不可能,有多奇怪。如果检验统计落在了备择假设所预示方向的抽样分布的尾部,就说明这个结果远远不同于原假设的预期。
通过分析样本统计量的抽样分布,我们可以计算出在原假设为真的前提下,样本点估计等于目前样本统计量的取值或者尾部更远、更极端取值的概率。这个概率就是P值。
P值就是当原假设为真时,得到目前样本观测值或与备择假设方向一致的更极端结果出现的概率。
P值越小,说明概率越小,也就是在原假设为真的情况下,得到目前这种观测值的概率很小。小到一定程度时,我们可以直接推翻原假设。P值越小,反对原假设的证据就越强。
结论:
P值对反对原假设的证据进行了总结,结论则需要返回到具体问题,解释P值告诉了我们什么。还需要对是否应该拒绝原假设做出决策。
大多数研究需要一个很小的P值以拒绝原假设,比如P<=0.05。这时,我们就说结果在0.05的水平下显著。0.05就是显著性水平,或者α水平。它代表如果原假设为真,那么得像观测值这样极端,甚至比它还要极端的统计量的概率不会超过0.05
均值的显著性检验:
在原假设为真的条件下,我们认为总体均值为μ0,于是x̄的均值应该为 μ0 。
我们认为样本具有随机性,不同样本会产生不同的有关总体均值的估计,这些不同估计的离散程度也就是样本均值的标准差,由标准误来表示。抽样分布的标准误为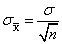 。但σ未知,于是用样本标准差s代替,就有了估计标准误
。但σ未知,于是用样本标准差s代替,就有了估计标准误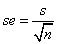 ,于是就有了检验统计量
,于是就有了检验统计量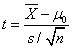 (这是T统计量,不是t score)
(这是T统计量,不是t score)
补充一下Z检验(U检验)与T检验的区别
高中的时候,还有可汗学院首先讲的都是Z检验,也称U检验。
Z检验是有条件的,要么样本量足够,要么知道总体标准差。它比T检验好用就好用在它有同一个临界值,而T检验临界值标准不同。
但如果条件不满足样本量足够,或者总体标准差未知时,学生T检验就更好了。
学生T检验主要用于样本量<=30,总体标准差未知的正态分布资料。
Z检验和T检验都会有P值
注意:在算置信区间所用的z和t,是z score和t score,而不是Z统计量、T统计量。对于数值型变量,最关注的就是数据的中心在什么地方。
那么这里数据类型是数值型。
原假设:总体均值μ = 某个特定的取值μ0
备择假设:μ≠μ0(这里是双尾,当然也可以μ>μ0,μ<μ0)
然后计算当μ=μ0时的T统计量T,如果是双尾,则计算P(t<-T)+P(t>T),如果P<0.05,则说明在原假设为真的情况下,得到眼前样本(或比这个样本还极端的)的概率小于0.05,说明总体均值≠μ0,应该拒绝原假设。
有的题会告诉某一总体服从正态分布,某一样本的均值、标准差和样本量。让求证明总体均值小于45所进行的假设检验的p值是多少。这时需要手动算T统计量,然后用 pt() 函数,输入T统计量和自由度去计算P值。
具体例子:

ladder <- read.csv("ladder.csv", header = T, sep = ",")
t.test(ladder$class, mu = 5) //原假设μ=5
如果想做单尾检验,则需要加alternative参数,左尾检验是less,右尾检验是greater
t.test(ladder$class, alternative = "less", mu = 5)上面这个例子是一个双尾检验,我们关注样本点估计是不是显著的不同于原假设。但在实际研究中,我们经常会有一定倾向性,认为点估计在某一个特定方向上显著的不同于原假设。如减肥干预,原假设是体重不变,备择假设是体重减轻。所以这种情况下应该用单尾检验,这个时候更注重的是样本观测值是否显著小于原假设。
比例的显著性检验:
既然用比例,那数据类型必然是分类变量。样本量需要足够大,样本比例的抽样分布才能近似服从正态分布。
原假设:π=π0
备择假设:π≠π0(这里是双尾,当然也可以π>π0,π<π0)
样本量足够大时,我们就能使用中心极限定理,就可以认为样本比例服从正态分布,这个正态分布的均值就是Π,Π就是总体的比例。这个正态分布的标准差就是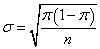 ,样本比例就服从这个正态分布
,样本比例就服从这个正态分布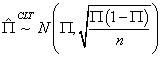
标准计分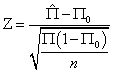 ,那么这个标准积分服从一个均值为0,标准差为1的正态分布
,那么这个标准积分服从一个均值为0,标准差为1的正态分布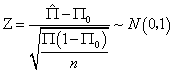 ,这就是Z统计量。
,这就是Z统计量。
在原假设为真的情况下,样本比例估计的标准误为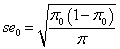 ,比如下面例子的原假设是0.5,那么π0=0.5,带进去算样本比例估计的标准误。注意,这里不是带样本的比例,而是假设(猜测)的总体比例。
,比如下面例子的原假设是0.5,那么π0=0.5,带进去算样本比例估计的标准误。注意,这里不是带样本的比例,而是假设(猜测)的总体比例。
举个例子:

pnorm(1.39) //是得到Pz在标准计分小于1.39的情况下得到的值——P(Z<1.39)。
但是要得到Pz在标准积分大于1.39的情况下得到的值——P(Z>1.39),,那么需要将lower.tail这个参数设置为F,表明要upper tail
pnorm(1.39, lower.tail = F)
最后得到的P值需要乘以2,如上图显示的P=0.08,乘以2等于0.16在这个例子中,P=0.16,大于0.05,所以原假设π=0.5也是可能信服的。
但这种情况下,结论通常报告说,不拒绝原假设,因为数据并不反对原假设,但绝不代表支持原假设。
原假设永远是想拒绝的假设,当样本量提高时,P值会受影响。样本量越大,样本统计量的标准误就会越小,说明样本统计量与原假设参数值之间的差距更大程度上来自于真实的差异,而非样本误差。
检验中的错误类型:
说说在做显著性检验时可能犯错误的类型和每种错误发生的概率。我们用小小有限样本去猜测大大的无限总体,就会存在犯错误的风险。
| 现 | 实 | ||
|---|---|---|---|
| H0为真 | Ha为真 | ||
| 决 | H0为真 | √(1-α) | ×(β) |
| 策 | Ha为真 | ×(α) | √(1-β) |
第一类错误:中文叫弃真,在现实中原假设为真的情况下把它扔掉了。α对应的是第一类错误。
第二类错误:中文叫取伪,在现实中原假设为假的情况下却没有拒绝。β对应的是第二类错误。
一般情况下是不想犯错误的,想α和β都小,唯一的办法是增加样本量。
显著性检验的局限性:
统计学意义上的显著并非神器,一个很小的P值,如P=0.001可以告诉我们样本观测值给我们足够证据反对原假设,但很可能,这在实际应用中没有任何意义。有时候显著性检验还不比置信区间有用,至少置信区间还提供了一个取值的范围。比如术后干预生活能力得分,比如样本得分均值为32,对照组为30,我们可以很用统计学去拒绝干预与不干预一样,但我们研究的问题是术后干预到底有多大帮助。
# 两组比较和多组比较
很多时候我们关注目标变量或结果变量在不同组别之内的取值。对于数值型变量,我们关注两组的均值是不是一样,对于分类型变量我们研究两组的比例的区别。
两组比较
由响应变量和解释变量构成的双变量分析(二元分析):
两个参与比较的组别自然的构成了一个二分变量(Binary Variable/Dichotomous Variable)。在比较男女家务劳动的例子中,这个变量是性别。
两组比较是二元分析的一种类型。二元分析研究的是两个变量之间的关系。二元分析有很多方法,但当结果变量是定量型或数值型,解释变量是组别的时候,就回归到两组比较的问题。
两组比较:对某种类型的结果变量的分析是按照另一个变量的不同分类进行的。我们所关注的、实际上进行比较的结果变量(Outcome Variable)叫响应变量(Response Variable)。定义组别的变量叫解释变量(Explanatory Variable)。
相依样本与独立样本
相依样本:某些研究在两个或多个时间点上比较均值和比例,如纵向研究(Longitudinal Study)/追踪研究。这种纵向研究呢实际上追同一个人每两年问他一次,那这一个人的记录会在不同样本中出现。这种时候样本就不是完全独立了,这时候就叫相依样本。
这类研究所收集的样本在不同时间点的研究对象是相同的,称为相依样本。更广义的说,当不同样本的研究对象发生了某种自然匹配的时候,样本也成了相依样本。如双胞胎、夫妻、家庭成员。
独立样本:很多情况下样本间是独立的,也就是说一个样本的观测对象独立于另一个样本的观测对象。
假设我们想评估某种新的辅助教学的方法是否有效果,就有两种设计。相依样本和独立样本的设计就不同。相依样本可以设计成,同一个班先测试一次,再用新教学方法三个月后再考一次。独立样本可以设计成,生成随机数将学生分为两组,一组使用原来的方法教学,二组使用新方法教学,三个月后考一次。那这种样本设计属于实验性研究。
大多数社科研究是观察性研究。观察性研究经常用到一种数据叫横截面数据。横断面研究是在某一特定时间对某一范围内的人群,以个人为单位收集和描述人群特征。
区分相依样本和独立样本的原因是,不同样本之间的标准误不同。
估计的差异及其标准误
估计的差异:
样本1和样本2的均值分别为y1,y2,那么(y1-y2)就构成了总体差异(μ1-μ2)的一个点估计。
两个独立样本之间的差异(y1-y2)的估计标准误为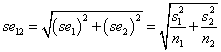 ,这只是用减法来计算两样本的差异。
,这只是用减法来计算两样本的差异。
比较两比例或两均值的另一种方法是使用它们的比率,就是用相除的方法。当参数相等时,比率等于1,比率离1越远说明这两个数越不同。两个比例的比率称为相对风险(Relative Risk),通常用来比较两组不想要的结果,如比较城市和农村中糖尿病发病率的区别。
独立样本的比较:
分类数据:比较两组比例
有以下两种方法
置信区间:
对大的独立随机样本,两个总体比例的差异(π2-π1)的置信区间为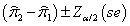 ,其中两样本比例差异的标准误为
,其中两样本比例差异的标准误为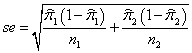 ,这样就可以求出差异的置信区间。如果这个置信区间涵盖了0,则说明π2-π1=0是有可能的。
,这样就可以求出差异的置信区间。如果这个置信区间涵盖了0,则说明π2-π1=0是有可能的。
关于 π2-π1 的显著性检验:
原假设是认为π2=π1,此时我们关注的是样本比例差异和原假设是否有显著不同。此时的标准误是在原假设成立时,即π2=π1时的标准误,用se0表示。
因为π2=π1,所以可以用一个共同的估计值——公共值,来估计样本比例。即把两个样本合成一个样本,然后算比例。之后就计算标准误,但是这时π2=π1,所以可以用一个 π来表示。然后计算Z得分,就得到了样本估计值和猜测的值相差Z个标准误的距离,然后求P值来做决策。
定量数据:比较两组均值
置信区间:
对于从均服从正态分布的两个组别中抽取两个独立随机样本,μ2-μ1的置信区间为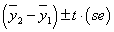 ,其中估计的差异的标准误为
,其中估计的差异的标准误为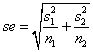 ,t分数的取值根据置信水平而定。求出置信区间。看看置信区间是否包含0,如果不包含0,则说明有95%的信心认为两组样本的均值不相等。
,t分数的取值根据置信水平而定。求出置信区间。看看置信区间是否包含0,如果不包含0,则说明有95%的信心认为两组样本的均值不相等。
例题:
例1.GSS数据从486名女性和354名男性中获取的数据显示,女性和男性分别有8.3(s=15.6)和8.9(s=15.5)个好朋友。如果用置信区间的方法研究男性好友平均数是否大于女性这个问题,那么我们所应构造的置信水平为95%的置信区间应是什么?
置信区间等于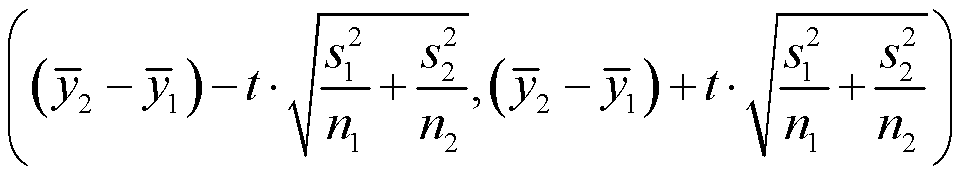 ,带入具体数值得
,带入具体数值得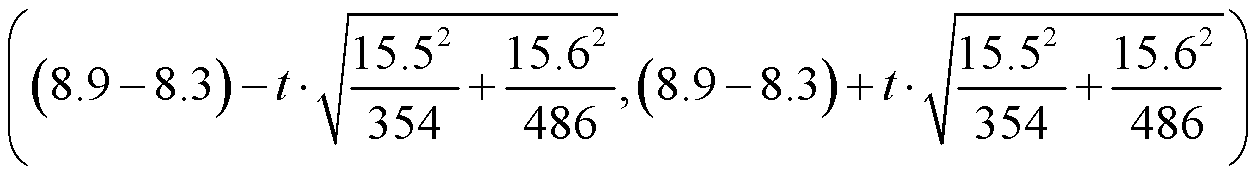 ,当自由度足够大时,去查Z表就可以了,95%对应等于1.96,代给t,计算出结果。感觉这里t写成z更合适。
,当自由度足够大时,去查Z表就可以了,95%对应等于1.96,代给t,计算出结果。感觉这里t写成z更合适。
相依样本的比较:
当样本1中的每个观测值都与样本2中的观测值匹配时,相依样本就形成了,由于匹配的缘故,来自相依样本的数据有时也被称为配对数据(Matched Pairs),相依的两个样本中有相同的研究对象/个体,前面提到追踪研究所产生的样本是相依样本,另一种类型的相依样本发生于对同一个研究对象进行两种刺激干预,称为交叉型研究(Cross-Over Study)
比较两组相依样本的均值
计算过程课程没有展示,只展示了计算代码。
mobile <- read.csv("mobile.csv", header = T)
attach(mobile)
boxplot(yes, no, names = c("Cell Phone", "No Cell Phone"), xlab = "Reaction Time", horizontal = T)
t.test(yes, no, paired = T, alternative = "greater") //paired参数表示是否有配对数据。添加alternative参数是因为我想证明用了手机会比不用手机反应时间长,就是yes > no在有选择的情况下,用相依样本更合理,原因如下:
- 可预见的潜在偏差被控制了
- 相依样本的样本均值差异的标准误小于独立样本
比较两组差异的其他方法
比较相依样本的比例,会用到麦克尼马尔检验(Mcnemar Test)
比较小样本的比例,会用到费歇尔精确检验(Fisher’s Exact Test)
当总体分布不是正态分布,样本量足够大时,抽样分布仍然服从正态分布。然而在小样本情况下,前面方法的适用性就有待考量了,这时候可以考虑对总体分布不做假设的非参数方法。如在对两个小样本均值进行比较时,可以使用Wilcoxon Mann Whitney Test
多组比较:方差分析
分类变量和数值型变量(定类-定距)变量间关系的研究在社会科学中很常见。比如职业与收入的关系、户口特征与生育意愿、国家与各经济发展指标间的关系、地区与平均寿命关系、工资与性别歧视问题。
当分类变量只有两种可能取值时,问题就简化成了前面所说的两组比较中均值、比例比较的问题。但实际问题中类别不止两类,这种情况下,就要用到方差分析(Analysis of Variance,ANOVA),虽然名字叫方差分析,但不是研究方差的,方差分析的目的是检验总体间的均值是否相同(因为分析多个分类类别,T检验不够用了),其检验手段或方法是通过对方差的分析实现的。
一元方差分析:
所谓一元,指只有一个定类的自变量,因变量是数值型变量。定类变量只有一个,但可以有很多个分组(分类),比如变量为专业,那么分组就有计算机学、非计算机学等分组(分类),每一个分组(分类)对应一个数值型因变量,比如工资。
一元方差分析检验统计量构建:
观测总数为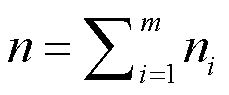 。第i类样本的组平均值(把变量的每一个分类当作一个组)为
。第i类样本的组平均值(把变量的每一个分类当作一个组)为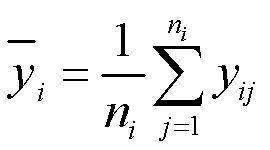 。
。
总平均值为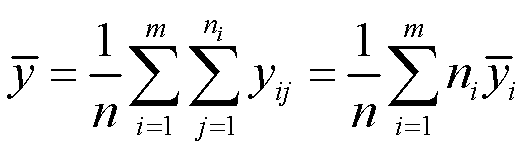 ,总平均值实际上是把所有类别对应的y加起来除以总数。
,总平均值实际上是把所有类别对应的y加起来除以总数。
总平方和(SST)是全体观测值yij对总平均值的离差平方和,为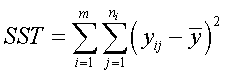 ,就是每个y值去减平均值的平方,然后加起来。
,就是每个y值去减平均值的平方,然后加起来。
组内平方和(SSE)是各观测值对本组平均值离差平方和的总和,为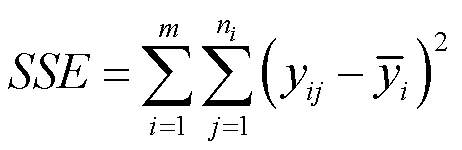 ,所有观测值都要对应到它的组里去算,最后加起来得到组内平方和。
,所有观测值都要对应到它的组里去算,最后加起来得到组内平方和。
组间平方和(SSB)是观测组的组平均值对总平均值的离差平方和,为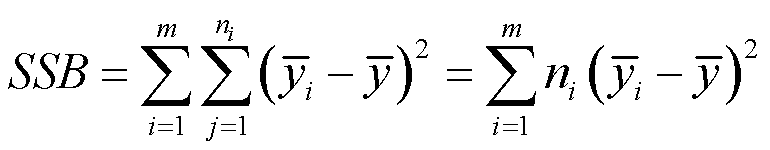 ,所有观测变量都要执行一次它所在的组平均值对总平均值的离差平方和,最后都加起来。
,所有观测变量都要执行一次它所在的组平均值对总平均值的离差平方和,最后都加起来。
三平方和对应关系:SST = SSB + SSE,实际上如果想证明不同分类确实对y有影响,那么我希望差异来自组间。
接下来使用F检验,在原假设(零假设)成立的条件下,以下统计量将满足分子自由度K1=m-1,分母自由度K2=n-m的F分布
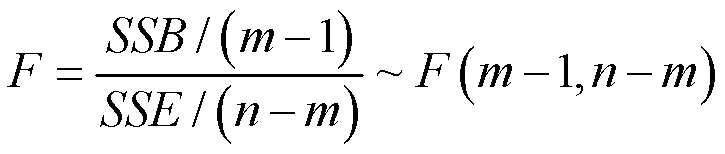
分子分母的SSB和SSE都除以了它们各自对应的自由度。如果我们希望差异来自组间,那么F的值越大越好。
若F>Fα则拒绝原假设,若F<Fα则不拒绝原假设。
注意:当方差分析拒绝了原假设,接受备择假设时,它表明有一个以上的类别,其均值不等,但它没有告诉我们是哪一对,哪几对均值不等。为此,统计学家提出了一系列的解决方法,如LSD法、Bonferroni法、Tukey法、Scheffe法、S-N-K法。
occupation <- read.csv("occupation.csv", header = T)
attach(occupation)
boxplot(income ~ occupation, data = occupation)
bartlett.test(income ~ occupation, data = occupation) //进行方差分析的时候有两条非常重要的检验,一是等方差性检验,一条是正态检验。该函数进行等方差性检验。该函数原假设就是各组方差相等。
如果等方差性检验通过了,那么可以相对安全得进行方差分析。
m1 <- aov(income ~ occupation, data = occupation)
summary(m1)
如果结论中P值很小,则拒绝了每组的均值相等的原假设。注意:方差分析的目的是对比均值的,不是对比方差的。# 变量间的关联分析
寻找变量间的关联是很多科学研究的重要目的,在统计学上,当响应变量的分布在某种程度上随着解释变量取值的变化而变化,那我们就认为两变量之间有关联。比如在上面,关注响应变量的取值是否随着组别的不同而不同,这个组别就是自变量。
有两个组时,两组比较使用T检验或Z检验。当有多个组时,就是方差分析,用F检验。
研究两变量关联时的可能情况

- 如果响应变量是定量型的,解释变量是分类型的,且解释变量只有两组分类,那么用比较两组均值的方法,也就是T检验。如果分类大于两组,那么用到的是方差分析ANOVA,F检验。
- 如果响应变量是分类型的,解释变量也是分类型的,且解释变量只有两组分类,那么用到上面讲的比较两组比例的方法。如果分类大于两组,那么会用到下面将要讲的方法,卡方检验。这会涉及到列联表的知识。
- 当响应变量和解释变量都是定量型的,就很理想了,因为得到的信息是最多最全的,用到的统计方法是相关系数(Correlation Coefficient)。
- 当响应变量是分类型的,解释变量是定量型的,会用到相对高级的统计方法体系,叫广义线性模型。
# 两个分类变量的关联分析
当分类变量是名义型变量的时候,用到的是卡方检验,画列联表。
当分类变量为定序型变量的时候,用到的是γ系数或其他方法。定序型变量就是从非常不满意到非常满意,从0到10打分。下面只讲了名义型分类变量的情况。列联表:显示了两个变量在所有可能结果上观察到的研究对象的数量。以下是一个非常典型的2乘3(2行3列,2 by 3)的列联表:每行和每列所对应的行和列和被称为边际分布(marginal distribution)。这里政党身份的边际频数就为959、991、821。
| 政党身份 | ||||
|---|---|---|---|---|
| 性别 | 民主党 | 独立人 | 共和党 | 总数 |
| 女 | 573 | 516 | 422 | 1511 |
| 男 | 386 | 475 | 399 | 1260 |
| 总数 | 959 | 991 | 821 | 2771 |
但我们要研究的是性别和政党属性间有什么关系,光靠观察频数是不够的。我们实际想知道,是不是不同性别中,政党属性的比例是不同的,这就需要条件分布了。条件分布指分别在男性和女性中各政党属性所占的比例,也就是以性别为条件,政党属性的样本分布。
| 政党身份 | ||||
|---|---|---|---|---|
| 性别 | 民主党 | 独立人 | 共和党 | |
| 女 | 38% | 34% | 28% | 100% |
| 男 | 31% | 38% | 31% | 100% |
当然也可以以政党属性为条件,看性别的分布。但在实际应用中,这是要看研究问题是什么的。我们标准化的以自变量为条件,看因变量在自变量不同取值时样本分布的区别。在建立选题的时候是有假设的。这里的研究问题是性别与政党属性的关系(假设是,性别对于政党属性的影响,性别影响了政党属性,而不能反过来说,政党属性影响了性别),性别是自变量。如果性别不同,条件分布不同,则可以说性别对政党属性有影响。如果在比较两分类变量时,响应和解释不清楚,那么以谁为条件关系不大。
以上表为例,在描述出条件分布后,我们看到这些百分比略有不同,但也不好说就是性别产生了影响,我们需要系统的证明。我们想知道是不是性别不同,党派属性的分布不同,这时就要用到统计上独立和统计上相依的概念了。
统计上独立:如果两分类变量中,一个变量在另一个变量的每个分类中,它的总体条件分布都相同(各分类百分比相同),这两个变量就是统计上独立的。
统计上相依: 如果两分类变量中,一个变量在另一个变量的每个分类中,它的总体条件分布不同,这两个变量就是统计上相依的。
无论是统计上的独立还是相依,都是指总体独立或相依。如果眼前的数据就是总体数据,那么只要看到各类百分比不同,那就可以说两个变量是有关系的。但我们得到的只是样本,我们需要用小样本来推测大总体。而且,即使总体是独立的,我们也不会期望看到完全相同的样本条件分布。因此需要进行一个显著性检验,来推断统计上独立或相依。
显著性检验
在这里进行显著性检验来推定总体变量是否独立或相依。只要是显著性检验,就有以下五个部分:
- 假定:随机抽取,样本量足够大
- 假设:H0:独立 Ha:相依
- 检验统计量:样本统计量和理论假设之间的差距
- 计算P值
- 得出结论
观测频数与期望频数:设f0表示列联表中每个单元格的观察频数。设fe表示一个期望频数。它是在变量相互独立时我们期望看到的每个列表单元的频数。它等于(行和*列和)/样本总数。列联表里每一格都能算出期望频数。每一个期望频数和观测频数作比较,就是构建检验统计量的过程。下面讲讲严谨的卡方统计量是怎么构建的。
检验统计量:卡方统计量 Chi-square(χ2)statistic
H0:变量之间是统计上独立的。Ha:变量之间是统计上相依的。
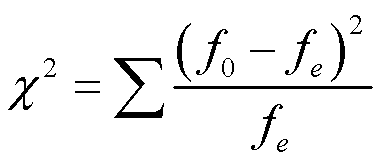
f0就是观察频数,fe是期望频数。(f0-fe)的平方,是用来看距离的,除以fe相当于标准化的过程,为了解相对区别。对每一个格都计算出相对差异。列联表里有多少个格就会有多少个差异,所以用Σ加和。
如果期望频数和观察频数相距甚远,则卡方就会很大。也就是说,如果实际上两个变量相关性很强,那么观测到的f0和fe的差距就会非常大,因为零假设是统计上独立,fe也是假设统计上独立求得的值。那么卡方值越大,说明实际离理想之间越远,则越有证据证明原假设为假。
当然,以上都是对距离的总结,接下来进行一个对概率的总结,也就是求P值。在求P值之前需要先了解一下卡方分布的知识。

对于大样本,刚才我们所建立的统计量的抽样分布是卡方概率分布,它集中在实数轴正方向,它的分布形态取决于自由度。卡方检验要求各个单元的期望频数fe应超过5.
- 均值=自由度
- 标准差=自由度开根号
- 自由度=(r-1)(c-1),行列数越大,df值越大,χ2值越大
如果抽到一个样本,然后这个样本的检验统计量比较大,就可以认为在原假设为真的情况下,得到目前观测到的卡方值的概率是比较小的,于是推翻变量独立的那个原假设,证明出变量之间是有关系的。那么卡方值需要多大,我们才可能认为不是样本随机性,而是总体变量确实是有关系的呢?这就需要概率总结,求P值。
以性别对政党属性影响那个例题为例,建立检验统计量:
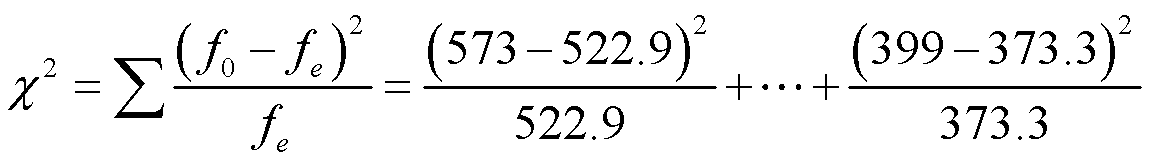
计算得出χ2=16.2,其对应的自由度df=(2-1)(3-1)=2,对于自由度为2的卡方分布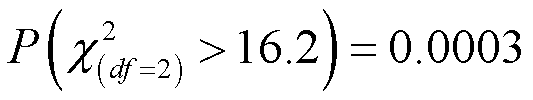 ,这个值显然小于0.001,也就是说在原假设变量统计上独立为真的情况下,得到这样一个列联表的概率是非常小的,提供了极强的证据来反对零假设,得到在总体里政党身份和性别很可能有关联。
,这个值显然小于0.001,也就是说在原假设变量统计上独立为真的情况下,得到这样一个列联表的概率是非常小的,提供了极强的证据来反对零假设,得到在总体里政党身份和性别很可能有关联。
row1 <- c(573, 516, 422)
row2 <- c(386, 475, 399)
table <- rbind(row1, row2)
chisq.test(table)
如果已经计算出χ2,也知道自由度,那么使用pchisq()函数就可以得到P值了
pchisq(q = 16.2, df = 2, lower.tail = F) 这个lower.tail = F是我想知道卡方大于某个数的P的取值,如果等于默认的T,得到的概率就是卡方小于某个数的P的取值。这个函数是求P值的。例题:下表取自2006年美国一般社会调查中交叉分类的幸福(HAPPY)和婚姻状况(MARITAL)。请使用R软件对婚姻状况及幸福两变量进行卡方检验,得到的卡方检验值及p值分别是多少?
row1 <- c(600, 720, 93)
row2 <- c(63, 142, 51)
row3 <- c(93, 304, 88)
row4 <- c(19, 51, 31)
row5 <- c(144, 459, 127)
table1 <- rbind(row1, row2, row3, row4, row5)
rownames(table1) <- c("结婚", "丧偶", "离异", "分居", "从未结婚")
colnames(table1) <- c("很幸福", "相当幸福", "不太幸福")
chisq.test(table1)# 两个定量型变量的关联分析:相关系数
下面的#回归分析、#多元线性回归,都是在讲这个。
相关:变量间存在关系,但又不能完全确定的关系称作相关关系。在概率论和统计学中,相关(Correlation,或称相关系数或关联系数),显示两个随机变量之间线性关系的强度和方向。这里强调一下线性关系,线性关系Linear,是严格的直线关系,相关系数有很严重的局限性的,可以用相关关系检验纯的直线的关系。如果是曲线,则用相关关系很难分析出来。
对于不同数据的特点,可以使用不同的系数。最常用的是皮尔逊积差相关系数(Pearson’s Product Correlation Coefficient),其定义是两个变量的协方差除以两个变量的标准差(方差的平方根),对于样本量为n的一组变量x和y,公式是这样的:
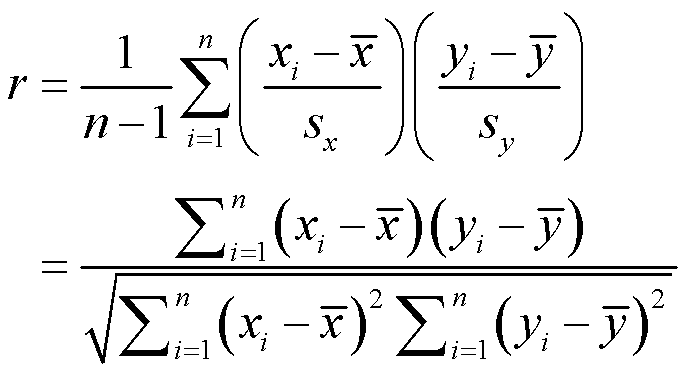
从公式可以看到,变量减均值除以标准差,得到的是标准积分。x的标准计分乘以y的标准积分再都加起来除以n-1,得到样本的相关系数。这个公式有个很好的特性,就是它必然是在-1到1之间的数,当r=0时,表明两个变量完全没有关系。
相关系数R的解读:城市计算PPT第6个里面写的,r=0是完全不相关,0<r<0.3是微弱相关,0.3≤r<0.5是低度相关,0.5<r<0.8是显著相关,0.8≤r<1是高度相关,r=1是完全相关。
注意:这里求到的相关系数,不是函数里面的x的相关系数!这里的相关系数代表的是相关性两变量有多相关。比如真正的函数一一对应如y=-0.5x+2,那相关系数就为1,因为都相关得一一对应是条线了,虽然是负相关,但相关系数是1.
# 回归分析
现代回归的作用:
- 描述两个变量之间的关系
- 探索自变量和因变量之间的因果关系
- 基于自变量的变化,预测因变量的取值
在大数据视角下,把统计学分为监督式学习和非监督式学习。线性回归是监督式学习里最简单的方法,也算是更高级回归的跳板。
做简单线性回归有一个假设,就是X与Y呈线性关系,依靠数学表达,我们可以把这个线性关系表达为
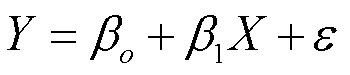
ε是扰动项,如果没有这个ε,那么XY就成完美的线性关系了。β0表截距(intercept),β1表示斜率(slope)。β0和β1和在一起就是模型系数或叫参数。
模型系数估计
在实际研究中,β0和β1都是未知的,我们需要用样本数据估计它们。用来衡量接近程度(closeness)的方法有多种,而普通最小二乘法(ordinary least squares, OLS)只是众多的找这条直线的方法之一。
普通最小二乘法
令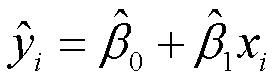 代表基于第i个X取值的Y预测值,那么
代表基于第i个X取值的Y预测值,那么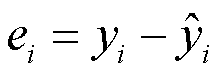 则代表第i个残差项(residual)。将所有的残差加和(由于正负抵消的问题所以这里用残差的平方),得到残差平方和(Residual sum of squares,RSS)定义为:
则代表第i个残差项(residual)。将所有的残差加和(由于正负抵消的问题所以这里用残差的平方),得到残差平方和(Residual sum of squares,RSS)定义为:
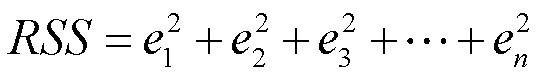
将e代换掉,得
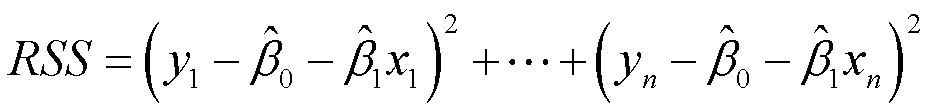
残差就是观测值到预测值的距离。我们的最终任务是找到一条直线,它离各观测点的距离越短越好。也就是说,要使RSS达到最小。使用最小二乘法得到可以使RSS最小化的β0hat与β1hat的取值:
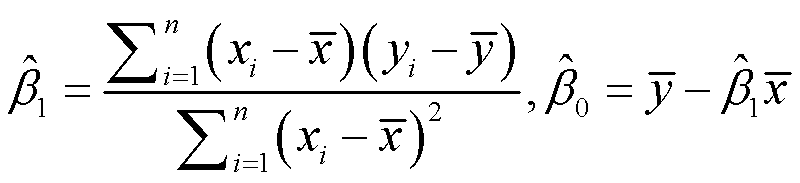
在模型的解释上,英文用的是 an additional $1000 spent on TV advertising is associated with selling approximately 47.5 additional units of the product.注意英文用的是is associated with,所以中文要用有关来解释。增加1000美金的电视广告预算与多销售约47.5个产品有关。
评价系数估计的准确性
X与Y的真实关系可以写成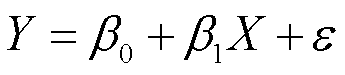 ,它定义了总体回归直线(population regression line),模型中的ε囊括了所有简单模型所错失的信息(a catch-all):
,它定义了总体回归直线(population regression line),模型中的ε囊括了所有简单模型所错失的信息(a catch-all):
- X与Y的真实关系也许不是线性的
- 也许还有其他的变量和Y取值的变化有关
- 测量误差
以上误差都有ε来表达,误差与x独立。除了以上问题,还有样本随机性的问题。我们抽取的样本,做的线性回归分析得到的斜率和截距,不一定等于总体回归系数。
无偏估计:如果从多个样本中获得的不同的模型系数进行平均,那么平均值应该刚好等于总体模型系数的真实值,即
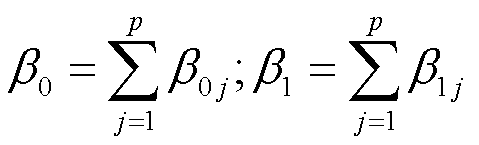
既然都提到了样本随机性,那么就像之前一样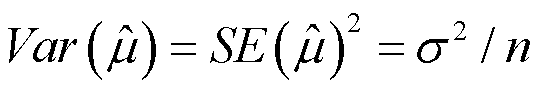 ,求β0和β1的标准误
,求β0和β1的标准误
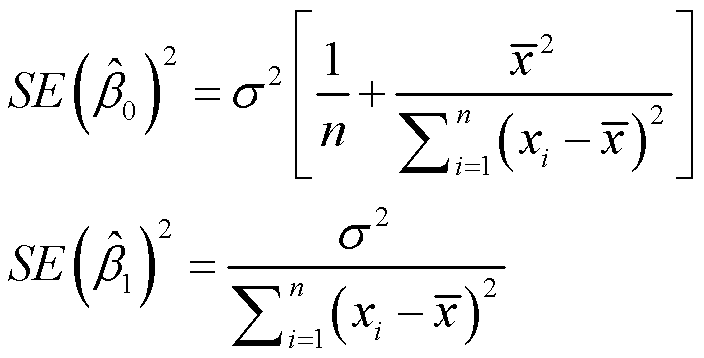
其中σ2=Var(ε),σ2是残差的方差,表示残差和残差之间的差异(为使这个公式严格意义上有效,我们需要假设来自每个观察值的εi与残差的方差σ2无关)。但这个ε针对的是总体的,那么σ2针对的也是总体的。所以真实情况下σ2是不知道的,于是在σ未知的情况下,又需要用现有的数据来估计它。这个估计叫做残差标准误(Residual Standard Error, RSE),RSE = sqrt(RSS/(n-2))。
那么对于线性回归模型,β1的95%置信区间约为
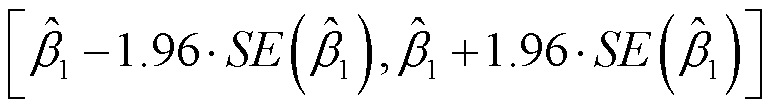
比如,在广告数据中,β0和β1的95%置信区间分别为[6.130,7.935]和[0.042,0.053]。这说明,如果没有任何电视广告,产品的销量会在6130到7935个之间。另外,每增加$1000电视广告投入,销量会平均增加42到53个。
回归系数的检验假设
H0:X与Y没有关系 ——> β1=0(斜率项等于0)
Ha:X与Y有关系——>β1≠0
检验统计量:
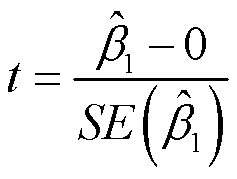
用到的是T检验,它测量β1hat与0之间相差多少个标准误。计算出T值后看看得到这个T值的P是多少,再进行决策。
评价模型的准确性
通过上面对回归系数的假设检验,一旦拒绝了原假设,认为X与Y是有关系的,那么接下来很自然的希望知道模型对数据的拟合程度。
线性回归的拟合质量由两个典型的统计量来评价:即残差标准误(Residual Standard Error,RSE)和判定系数(R2 statistic)
RSE是残差ε标准差的估计,可以理解为响应变量偏离回归直线的平均值。
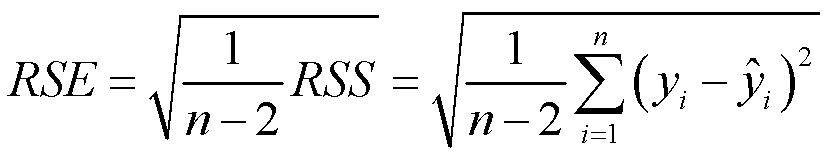
RSE提供了模型对数据拟合程度的绝对测量,什么是绝对测量?就是RSE是带单位的,单位和响应变量一样。如果把Y的单位从津巴布韦币换成科威特第纳尔,那RSE会成数量级的变化。所以我们无法清楚地确定到底多大的RSE可以被认为是可接受的。所以接下来我们讲讲判定系数R方。
以比例形式呈现的R2 statistic,它是被解释方差的比例,它的取值必然在0和1之间,并与Y的测量量级无关。比如R2=0.91,意思是y的变异中有91%可以由模型解释。
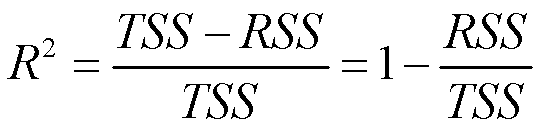
其中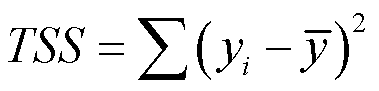 是总平方和(total sum of squares)。这个TSS看起来和方差就很像,实际上它除以个n就等于方差了。那TSS就是来自于响应变量的所有变化,RSS实际上是回归模型解释不了的那部分,TSS-RSS就是减去了解释不了的那部分,剩下的就是解释得了的那部分。那么R2的值越大,说明可以由回归模型所解释的那部分变异比例越高。于是认为模型的拟合越好。
是总平方和(total sum of squares)。这个TSS看起来和方差就很像,实际上它除以个n就等于方差了。那TSS就是来自于响应变量的所有变化,RSS实际上是回归模型解释不了的那部分,TSS-RSS就是减去了解释不了的那部分,剩下的就是解释得了的那部分。那么R2的值越大,说明可以由回归模型所解释的那部分变异比例越高。于是认为模型的拟合越好。
R2测量的是Y的变化中可以被X解释的比例(proportion of variability in Y that can be explained using X)。得到一个好的模型,并不是说要得到一个0.8 0.9的R2,大致有个越大越好的感觉就行。
R语言线性回归实例
用到的数据是MASS的Boston的数据,用到MASS和ISLR两个包。使用 fix(Boston) 可以弹出窗口看数据长什么样。使用 names(Boston) 也可以看到数据的列名。
m1 <- lm(medv ~ lstat, data = Boston) //房价中位数与地位做线性回归
names(m1) //可以查看m1包含的结果,毕竟summary(m1)展示不全
coef(m1) //该函数查看回归系数
confint(m1) //查看m1的置信区间
predict(m1, data.frame("lstat" = c(5,10,15)), interval = "confidence") //结果中fit对应的是yhat,lwr是lower limit,对应的是置信区间。给一个X的取值,所估计的Y的取值是Y的均值。Y均值的真实值会落在lwr和upr之间。
predict(m1, data.frame("lstat" = c(5,10,15)), interval = "prediction") //结果中fit对应的是yhat,和上面的一样。但上面式子结果的lwr和upr估计的是yhat的置信区间。而这条式子lwr和upr估计的是y本身的置信区间
plot(medv ~ lstat, data = Boston, pch = "b") //pch参数可以用来确定点的符号。如果想自定就输入"",用预置的符号就输入1到20
abline(m1) //向高级函数出的图中添加直线# 多元线性回归
假设有p个自变量,那么多元线性模型的表达式为:
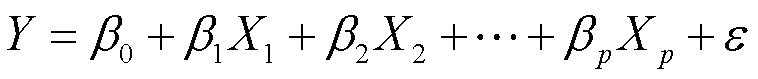
其中Xj代表第j个自变量,βj代表各自变量和响应变量间的数值关系。我们将βj解释为在其他自变量保持不变的情况下,Xj增加1单位,Y的平均增长量。
给定估计值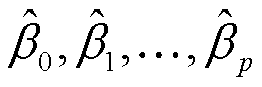 ,我们可以根据以下公式进行预测
,我们可以根据以下公式进行预测
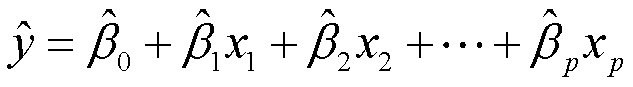
我们选择的取值,来使残差平方和达到最小值
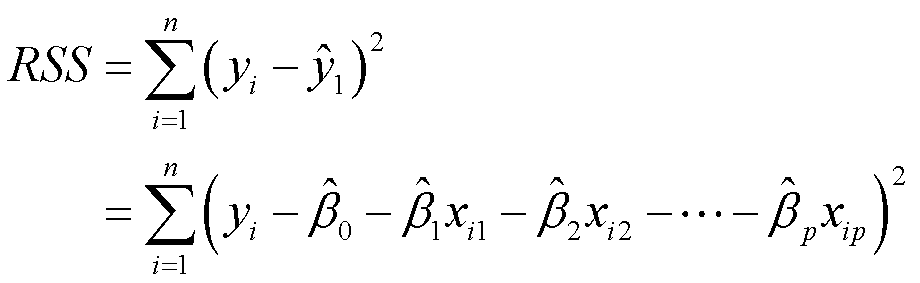
进行多元回归的结果可能会发现有的变量系数很小,p值也不显著。但把这些变量和响应变量进行一对一的回归分析又会得到显著的p值。这是因为,其实做一个所有解释变量与响应变量间的相关系数矩阵(correlation matrix)可以发现,有的解释变量和解释变量相关系数较大。把相关系数较大的解释变量放一个回归模型里面就分不清楚到底对响应变量的贡献来自于谁。这是后面会讲的共线性的问题——当模型里自变量相关程度特别高的时候,实际上是没办法区分这个影响到底来自于谁的。所以在建立多元回归模型的时候不能把本身高度相关的两个自变量随意扔到回归模型里面。
几个重要问题
- 几个自变量X1,X2,…,XP中是否至少有一个与响应变量有关(可以预测响应变量)?
- 是否所有的自变量都可以用来解释Y,还是仅有它们的一个子集有作用?
- 模型对数据的拟合程度有多高?
- 给定自变量的取值,响应变量的预测值应该是多少?这个预测值的准确性如何?
Q1:自变量与响应变量间是否有关系?
H0:β1=β2=…=βp=0
Ha=至少有一个βj是非0的
检验统计量:
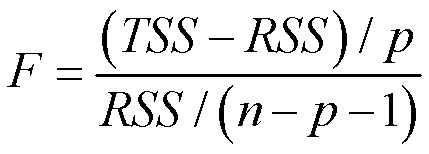
TSS(Total Sum of Squares)代表离差平方和,表示Y总体变异的情况。RSS(Residual Sum of Squares)代表残差平方和,表示线性模型不能解释的那一部分。(TSS-RSS)就表示可以由线性模型解释的部分。p代表的是有多少个自变量。所以(TSS-RSS)/p相当于每一个自变量对Y的贡献。分母RSS/(n-p-1)是残差平方和的均值,代表平均的不能解释的部分。
如果线性假设是正确的,对分母求期望就等于σ2:
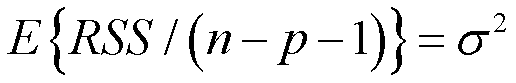
并且如果原假设H0为真,则对分子求期望也等于σ2:
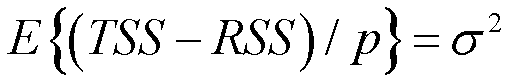
所以如果H0为真,那么分子分母期望值都是σ2,那么得到的F就是在1附近的数。如果H0为假,那么自变量对y是有影响的,就会面临大部分变异可以被模型解释,那么分子就会变得很大。所以F值越大,那就说明有更多证据证明至少有一个自变量和响应变量产生关联的。
思考:既然已经有了针对每个变量与响应变量Y关系的假设检验和p值,那么为什么还需要查看F检验结果?似乎只要有一个p值显著,就已经证明了至少有一个自变量与因变量相关了。答:然而实际上,这个逻辑推理是有瑕疵的,尤其是当模型中自变量的个数较大时。假设有100个自变量,它们均与响应变量无关,在这种情况下,大概有5%的p值可能仅因为样本随机性的缘故小于0.05(第一类错误,弃真)。
以上是关于第一个问题,很谦虚的假设,F检验其实并不是特别有力的,它是特别谦虚的,它就是想看看这个模型千错万错是不是至少有一个X与响应变量相关。
Q2:选择重要变量的问题
理想情况下,我们希望通过尝试建立不同的模型来对变量进行选择。最好的模型由不同的统计量来评价,可以用R2来比较,还可以用Mallow’s Cp,Akaike Information Criterion(AIC),Bayesian Information Criterion(BIC)以及adjusted R2.
然而,对于一个有p个潜在自变量的模型,我们可以产生2p个候选模型。即如果p=30,那么230=1073741824
这时就需要一个高效的自动选择模式,包括以下3种经典方法:
- Forward Selection 前向选择:把一个一个自变量加进去
- Backward Selection 后向选择:尝试把所有变量先都加进去,然后一个一个往下减
- Mixed Selection 混合选择:一方面相加一方面相减
Q3:模型拟合的问题
两个最重要的模型拟合数量测量值分别是:RSE和R2,RSE=sqrt(RSS/(n-p-1)),p是自变量个数,在一元线性回归中分母就是n-2(因为p=1),但有个问题,RSE的单位和Y一致,所以很难给出一个很清楚的区分RSE多大是大多大是小。所以用R2,R2越接近1模型拟合程度也好。
还有就是通过作图来看观测值和模型的距离,如果有一些部分特别近,有一些部分特别远,说明可能会有非线性的特征被错过了。通过可视化的方法会对模型有更好的理解。
Q4:预测问题
预测值的不确定性有3个来源:
- 对于系数的估计是来自于β0, β1, β2,…, βp的样本估计
- 在实际中,用一个线性函数来描述f(X)几乎都是对现实的近似,有时会更加复杂的模型形式。所以造成了一种可以被削减的误差(reducible error),叫做模型误差(model bias)
- 即使得到了总体真实值β0, β1, β2,…, βp,因为随机误差ε的存在,响应变量也无法被准确预测,我们将其称之为不可削减误差(irreducible error)
定性型自变量的处理
实际中,通常有些自变量是定性型的(qualitative)。
Example
信用数据记录了余额balance(个人信用卡平均欠账情况)和一些定量型自变量的情况:age(年龄),cards(信用卡持有数),education(受教育年限),income(收入:千美元),limit(信用卡额度),以及rating(信用评级)。另外还有4个定性型变量:gender(性别),student(学生状态),status(婚姻状况),ethnicity(族裔)。
面对这么多变量,在建模之前可以先画一个散点图矩阵。看两两变量之间的散点图。
pointsWithLinesFun <- function(x,y){
points(x,y)
abline(lm(y~x), col = "red")
}
pairs(longley, panel = points) //points()是画散点的低级绘图函数。pairs()用来画矩阵图。panel = pointsWithLinesFun相当于用自己写的函数来填充这个矩阵图。
除了graphics::pairs()函数,还有car::spm(),GGally::ggscatmat()和GGally::ggpairs(),都可以画散点图矩阵看到散点图会发现,定量型变量散点图可能会看出一点关系来,但定性型变量就不好看了。
建立虚拟变量
如果一个定性型变量只有两个分类/水平,我们只需建立一个有两种可能取值的虚拟变量(dummy variable)
如,基于性别变量,我们可以建立一个新的变量

于是
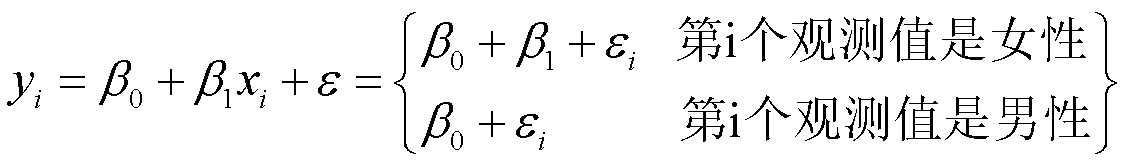
定性变量比定量变量难解释。这里β1代表的是男性和女性之间的差别。就是男性和女性在y值上的差别。假设yi是余额(欠账情况),那么女性的欠账情况比男性多β1。
潜在问题
构建多元回归模型的时候可能面临很多潜在的问题,这些潜在问题在传统的多元回归教科书上是被放在回归诊断那一章节。可以去看谢宇老师的多元回归的书。这里讲讲回归诊断一小部分内容。
鉴别和克服这些建模的时候存在的潜在问题非常具有艺术性。
回归是有一些要求的,在不满足这些前提假设条件下如果非要构建一个模型,这个模型也不见得是有效的。这些潜在问题和建模的时候的基本假设紧密相关。下面是存在的潜在问题:
- 响应变量与自变量间的关系非线性(要想使F检验成立,就要求自变量和因变量之间是线性关系,如果不是线性关系,不光是F检验,整个模型都是无效的。)
- 误差项间相关
- 误差项方差非常数σ2
- 异常值(Outliers)
- 强杠杆作用点(High-leverage Points)
- 共线性(Collinearity)
Q1:数据的非线性的问题
线性回归一定是有线性假设的,如果响应变量和自变量之间不是想象的那种线性关系,那么——
后果:模型估计的结论令人产生质疑;模型的预测准确性可能显著降低。
诊断:残差图(Residual Plot)。残差是观测值和预测值之间的距离,我们希望残差越小会好,还要求所有残差的均值应该等于0,同时残差和残差之间应该没有相关性。那么残差图理论上应该看不到可分辨的图案、趋势。图上的各点应该是散落各处的很随机的分布,同时它应该是以0为中心上下振动的。对没有趋势的残差图画一条线,我们希望看到这条线和0的那条线是重合的。

右图Quadratic表示平方,这是进行了转换后的残差图。
解决办法:在模型中对自变量进行非线性转换,如logX(取对数),sqrt(X)(开根号),和X2(取平方)。对于不同的数据形态,具体用哪种方法是不一样的。
Q2:残差项相关的问题
什么情况下残差项容易相关——对同一个个体测量很多次,或测量已经形成某种自然匹配的数。之前讲paired T-test也是这个问题。
后果:估计标准误被低估。残差标准误被低估会产生一种错觉——认为模型估计准确性特别高因为扰动很小离散程度很小。但实际上这种较低的标准误是因为残差项之间的相关性引起的。
诊断:画图(联系理论)。以经济时间序列数据为例,为什么残差项会产生相关性——理论上来讲经济时间序列是同一个解释变量在不同时间的取值,也就是同一个个体在不同时间收集的数据,那么不同观测值之间必然是有一定相关性的,所以需要画图检视残差与时间的关系。

ρ=0.0,代表残差项相关系数等于0的情况。ρ=0.5,残差项相关系数等于0.5的情况。
解决办法:多水平模型(multilevel analysis)等。
Q3:残差项方差非常数σ2的问题(Non-constant Variance of Error Terms)
对于残差项(误差项)的要求特别多,上面说要求没有相关关系。另外一个要求就是残差与残差之间的方差应该是与xi无关的常数。对于同一个X取值会有很多个Y,每一个Y和Y的预测值之间会有一个残差,残差和残差之间形成方差。有一个很重要的假设——不管X的取值是多少,这个残差的扰动应该是一致的且与X的取值是没有关系的,且是一个常数。如果不是常数,会产生不良后果——标准误的估计、置信区间的估计以至于后面的假设检验都会产生偏误。
诊断:残差图(是否有漏斗形funnel shape,左图)。如果残差项方差非常数,可以称为异方差性。残差图有漏斗形。那么就说明有异方差性。

解决办法:用凹函数(concave function)对Y进行转换,如logY或sqrt(Y);或改用加权最小二乘估计法(weighted least squares)
Q4:异常值(响应变量)
后果:可能对参数估计值产生影响(不一定,Y轴上的异常值不一定对回归直线产生影响),对RSE,R2等均产生偏误(一定)。
诊断:残差图;studentized residuals>3(每个残差ei除以其对于的估计标准误,如果大于3则认为这个点是异常值)
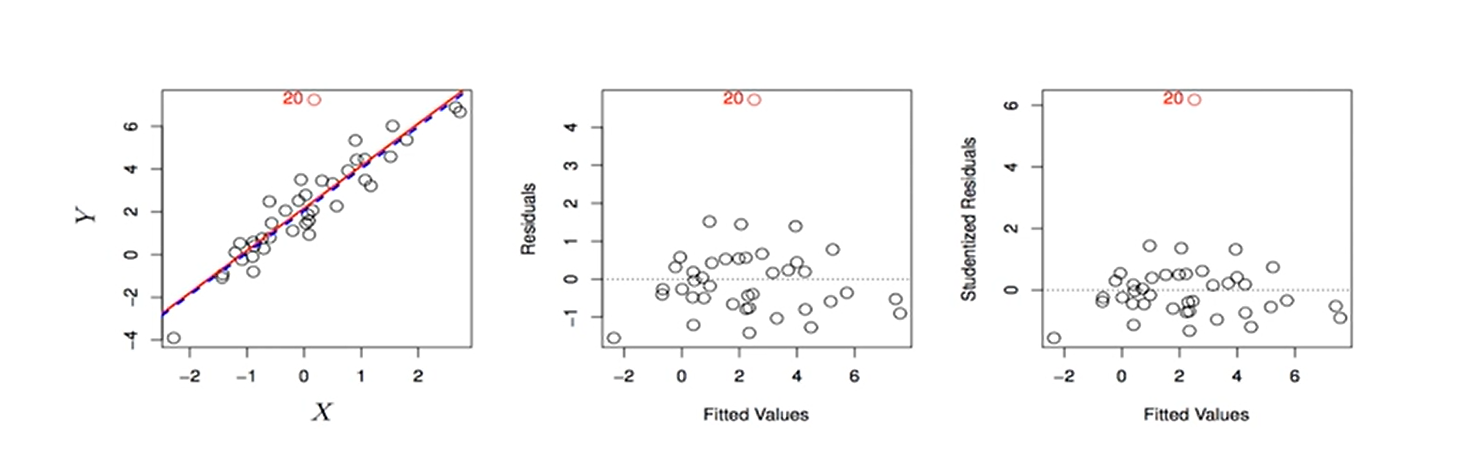
解决办法:如果很确定它就是很异常又没有其他理论可以解释的话那就删除掉,但要慎重,它的异常也可能是缺少重要自变量造成的,图中异常值只有一个,如果很多,那就需要考虑是不是某种非线性因素或其他因素产生了影响。
在R语言中:看plot(linearModel)输出的第四张图,看看Y轴的Studentized Residual有没有大于3的。
Q5:强杠杆作用(自变量xi上不寻常的点)
等号左边奇怪的数叫异常值,等号右边自变量不寻常的数叫强杠杆作用。
后果:影响回归模型估计值
诊断:leverage statistics hi > (p+1)/n,杠杆统计量,其中,p表示模型中自变量个数,n是样本量,i’(i撇)表示除去了第i个变量以外其他的变量。如果一套数据有200个观察值,就可以生成200个杠杆统计量,对于每个观测值都可以看它是不是异常。
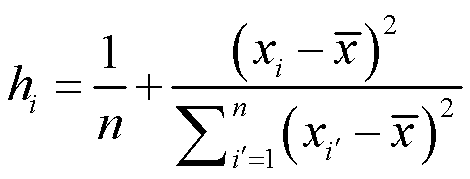
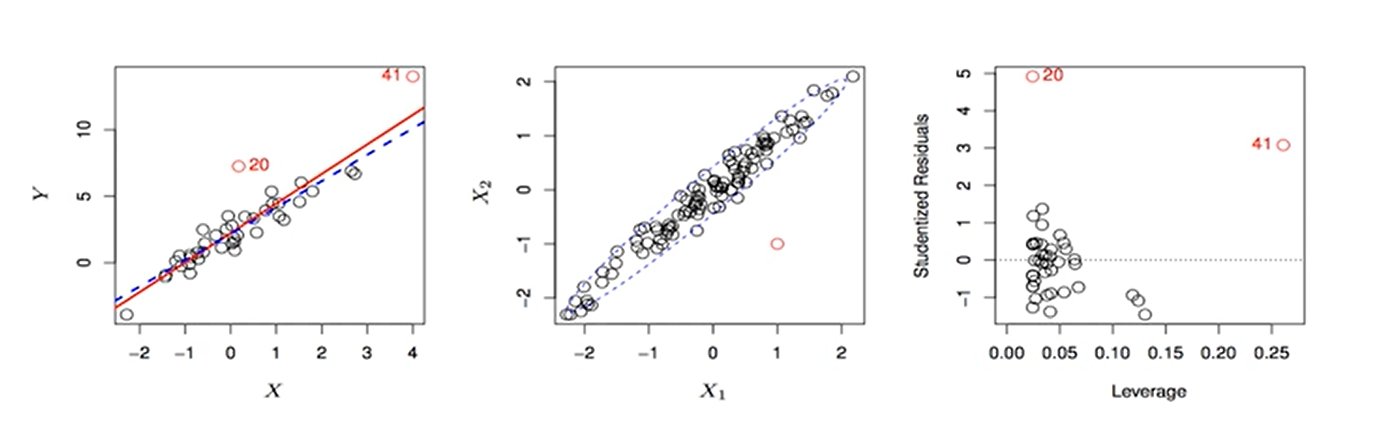
解决办法:删除。
在R语言中:看plot(linearModel)输出的第四张图,看看X轴的杠杆值有没有大于(p+1)/n的。
Q6:共线性(Collinearity)
这里举个之前的例子,
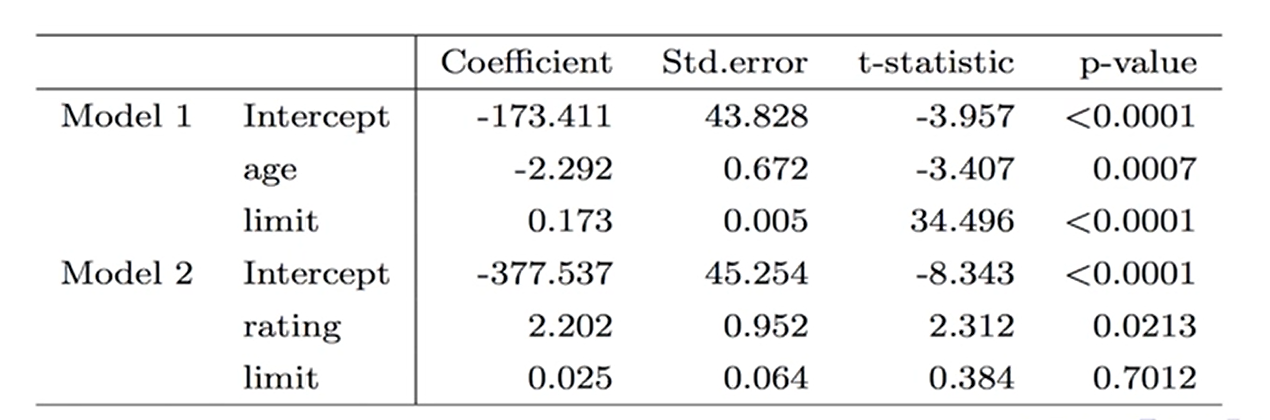
模型1研究年龄、限额与卡账的关系:年龄越大卡账会越少,卡的限额越高欠账也越高。limit标准误0.005,说明模型对限额与卡账估计系数的准确性比较高。
模型2研究信用评级、限额与卡账的关系:这两个自变量就形成共线性了,rating是的p值是显著的,但显著性不高。limit的p值直接就不显著了,标准误也大大膨胀了。加了一个高度相关的自变量rating后,就分辨不出到底rating对欠账起作用还是limit起作用。
后果:难以区分高度相关的自变量对响应变量的独立影响;降低模型系数估计的准确性,使系数标准误的估计增加
诊断:画自变量与自变量之间的相关系数矩阵,如果有其他自变量之间相关性都在0.0几左右,而某两个自变量相关系数到0.3 0.4,那么就要小心了;膨胀因子(variance inflation factor,VIF) > 10,用VIF来衡量到底某一个变量是否与模型里其他变量产生共线性,如果大于10则考虑剔除这个变量。
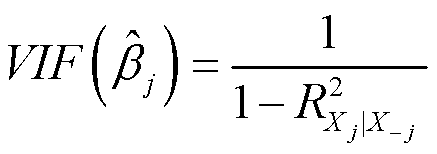
讲讲这个公式:βj hat是第j个自变量它前面的系数。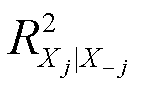 是把第j个自变量当成响应变量,用除了这个自变量以外的其他自变量对他进行回归的判定系数。这样就可以知道其他变量能不能很好解释这个自变量。如果存在共线性,那么其他变量可以很好代表这个第j个自变量。
是把第j个自变量当成响应变量,用除了这个自变量以外的其他自变量对他进行回归的判定系数。这样就可以知道其他变量能不能很好解释这个自变量。如果存在共线性,那么其他变量可以很好代表这个第j个自变量。
所以如果R2值很大,则说明模型具有共线性的问题了,1-R2就会变得小,再分之1,VIF就会变得很大很大。
所以如果VIF很大,大于10,则是共线性很强的证据。
解决办法:去掉一个问题变量;将两个变量合并(考虑实际意义)
# 用R语言进行多元线性回归
上面讲了构建多元线性回归的潜在问题,接下来讲一讲如何用R语言来进行多元线性回归以及用R语言检查多元线性回归的潜在问题。接下来使用LSLR、MASS、car包来讲一讲R语言的多元线性回归。
m1 <- lm(medv ~ lstat + age, data = Boston) //二元线性回归,medv是响应变量,lstat和age是解释变量
m1 <- lm(medv ~ ., data = Boston) //多元线性回归,用.表示把除了medv以外所有变量都加进去
m1 <- lm(medv ~ .-age, data = Boston) //用.表示把除了medv以外所有变量都加进去,然后用-把不需要的变量去除
summary(m1) //查看RSE、P、R方、回归系数等结果用 car::vif() 函数来计算膨胀因子来判断共线性。vif()会直接输出每个自变量的膨胀因子。大于10的剔除掉,或者合并。
library(car)
vif(m1)交互项
m1 <- lm(medv ~ lstat + age + lstat:black, data = Boston) //交互很简单,在两个变量之间加冒号就行
m1 <- lm(medv ~ lstat*age, data = Boston) //自变量加*是偷懒写法,相当于写成 lstat + age + lstat:age非线性转换
当响应变量与预测变量不是线性关系,则需要进行非线性转换——把非线性关系转换为线性关系。
m2 <- lm(medv ~ lstat + I(lstat^2)) //在编程环境中^有其他作用,所以前面加一个I把项目括起来,否则会报错
summary(m2) //如果和二次项也显著,那么说明做一下非线性转换是有好处的
anova(m1, m2) //使用anova()函数比较这两个模型哪个好,原假设是两个模型拟合程度一样好,一个显著的P值可以推翻原假设,说明加入二次项之后模型有非常显著的提高关于R中的符号,可以查看R语言学习记录中#笔记。关于 anova() 函数用来比较两个嵌套模型,参考anova()函数比较两个嵌套模型的拟合度。
分类型变量处理
这里用到ISLR包中的Carseats包,这个包有很多分类型变量。我们先来看一下这套数据
Sales CompPrice Income Advertising Population Price ShelveLoc Age Education Urban US
1 9.50 138 73 11 276 120 Bad 42 17 Yes Yes
2 11.22 111 48 16 260 83 Good 65 10 Yes Yes
3 10.06 113 35 10 269 80 Medium 59 12 Yes Yes
4 7.40 117 100 4 466 97 Medium 55 14 Yes Yes
5 4.15 141 64 3 340 128 Bad 38 13 Yes No
6 10.81 124 113 13 501 72 Bad 78 16 No YesShelveLoc这一列装的是分类型变量,用 class() 函数来查看这一列,可以清楚看到这是因子类型的数据。如果有些分类输入的是123等数值型数据,那么需要用 as.factor() 函数将它们转为因子类型。
m3 <- lm(Sales ~ . + Income:Advertising + Price:Age, data = Carseats) //lm函数自动将因子类型的ShelveLoc当作分类变量,且在结果中有ShelveLocGood和ShelveLocMedium,那么ShelveLocBad就是参照组。所以Good和Medium的回归系数都是相对参照组Bad来说的。
//输出:
//...
//ShelveLocGood 4.8486762 0.1528378 31.724 < 2e-16 ***
//ShelveLocMedium 1.9532620 0.1257682 15.531 < 2e-16 ***
//...
contrasts(Carseats$ShelveLoc) //使用contrasts()函数来查看虚拟变量是如何构建的
//输出:
// Good Medium
//Bad 0 0
//Good 1 0
//Medium 0 1
//可以看到,原来的变量取值在左边那一列,有3个。新生成的虚拟变量是Good和Medium。
//抽象的结果这样理解,假设说原来的变量为Bad,则在新的虚拟变量ShelveLocGood和ShelveLocMedium中都是0
//假设说原来变量为Good,则在新的虚拟变量ShelveLocGood为1,ShelveLocMedium为0,以此类推
//两个新建的虚拟变量足够代表原来三分类的变量# 响应变量为分类型解释变量为定量型的分析:广义线性模型
当响应变量为分类型变量,且只有两个可能取值的时候,即响应变量为2分变量(dichotomic variable)时,可以使用Logistic Regression。
# Logistic Regression
Logistic Regression可以用来研究人们是不是支持某个政策的关联因素,比如人们愿不愿意生孩子,人们愿不愿意买房等。那么支持等于1,不支持等于0….
分类问题
在之前讲到的(多元)线性回归中,线性回归要求响应变量为定量型变量。但在一些研究中,响应变量是分类型的,我们通过研究想预测响应变量会落入哪一个分类。这个分类有时候只有两类(是、否),有时候会有更多类型。这种预测通常是以落入某一特定分类的概率为媒介来实现的,用概率来判断可能会落入哪个分类。
研究落入哪种分类的方法其实有很多:Logistic Regression(Logistic回归)、Linear discriminant analysis(线性判别分析)、k-nearest neighbors algorithm(K近邻算法)等。
为什么在响应变量为分类型变量时不能用线性回归?
假设我们想根据症状对急诊室病人进行诊断,在这个被简化的例子中,我们的三种可能诊断为:中风、服药过量和癫痫。此时响应变量Y可以用定量型变量表示(如果用线性回归就是把响应变量当作定量型变量):

使用这种编码方式,就可以拟合一个线性回归的模型。然而,这种方式暗示了结果变量的排序关系,即癫痫>服药过量>中风,且它们之间等距。
基于概率建立模型
为什么要建立Logistic模型
响应变量为2分类型,把它表示为0和1后,Logistic Regression关注的是响应变量落入某一分类的概率,是基于概率建立模型而不是对可能取值(0,1)建立模型。
想象一下,如何建立概率与解释变量之间的关联?如果用线性模型,那当解释变量无穷大P就无穷大或者无穷小了。所以我们需要另外一种函数关系,使得对于任何X取值,P的取值都会在0~1之间。
实际上很多函数都满足这个要求,在Logistic Regression中,我们使用Logistic函数完成这种转换,即:
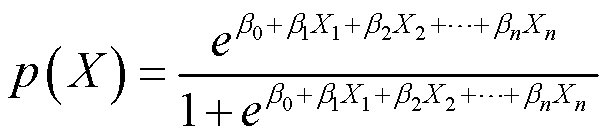
Logistic函数永远会生成一个S型曲线来描述X和p(X)之间的关系,且在Y方向上不会出0~1。
如何解读模型中的β0和β1?
将上面的公式稍做转换,就可以得到:
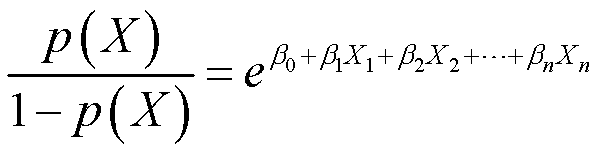
这里p(X)/(1-p(X))代表的是发生比,取值范围是[0,+∞),对上面等式两边同时取对数,有:
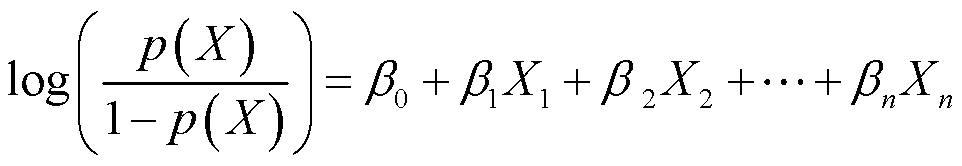
等式左边被称作对数发生比(log-odds或logit)。那么可以这样解释,在其他变量不变的情况下,X1增加一个单位,某事的对数发生比(log-odds)增加β1个单位。也就是说,在其他变量不变的情况下,X1增加一个单位,某事的发生比变为原来的eβ1。
可见,Logistic模型中,对数发生比同自变量成线性关系。
注意:
- p(X)与X并无直接的线性关系
- X增加一个单位时,p(X)的变化幅度根据X的取值不同而不同
- 然而无论X取值大小,回归系数为正,说明X增加p(X)增加,回归系数为负,说明X增加p(X)减少
回归系数的估计
回归系数β0, β1, β2,…, βn是未知的,我们需要根据样本数据对他们进行估计。
线性回归的估计使用最小二乘法,虽然我们可以使用非线性最小二乘法估计Logistic Regression的系数,但更恰当且被广泛使用的方法是极大似然估计法(Maximum Likelihood Estimate),它具有更好的统计属性(统计属性包括无偏性、一致性和有效性),最小二乘估计实际上是极大似然估计的一个特例。
极大似然估计法的基本思路
我们希望找到β0, β1, β2,…, βn的估计值,使得出现样本观测概率p(X)的可能性最大
这个基本思路可以通过似然函数体现:
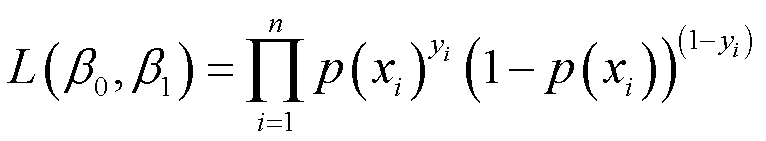
其中yi=0或1。我们选择β0hat和β1hat的取值,使得L(β0,β1)达到最大值。
预测
一旦得到系数估计,就可以很直观地计算响应变量某一分类发生的概率:
分类型自变量处理
之前在线性回归中提到了虚拟变量的问题,其实在做Logistic Regression时虚拟变量仍然存在。假设有个解释变量为是否是学生,如果是则这个虚拟变量的值为1,如果不是则这个虚拟变量的值为0。将这个是否是学生的分类变量放在模型里面做Logistic Regression,得到以下结果

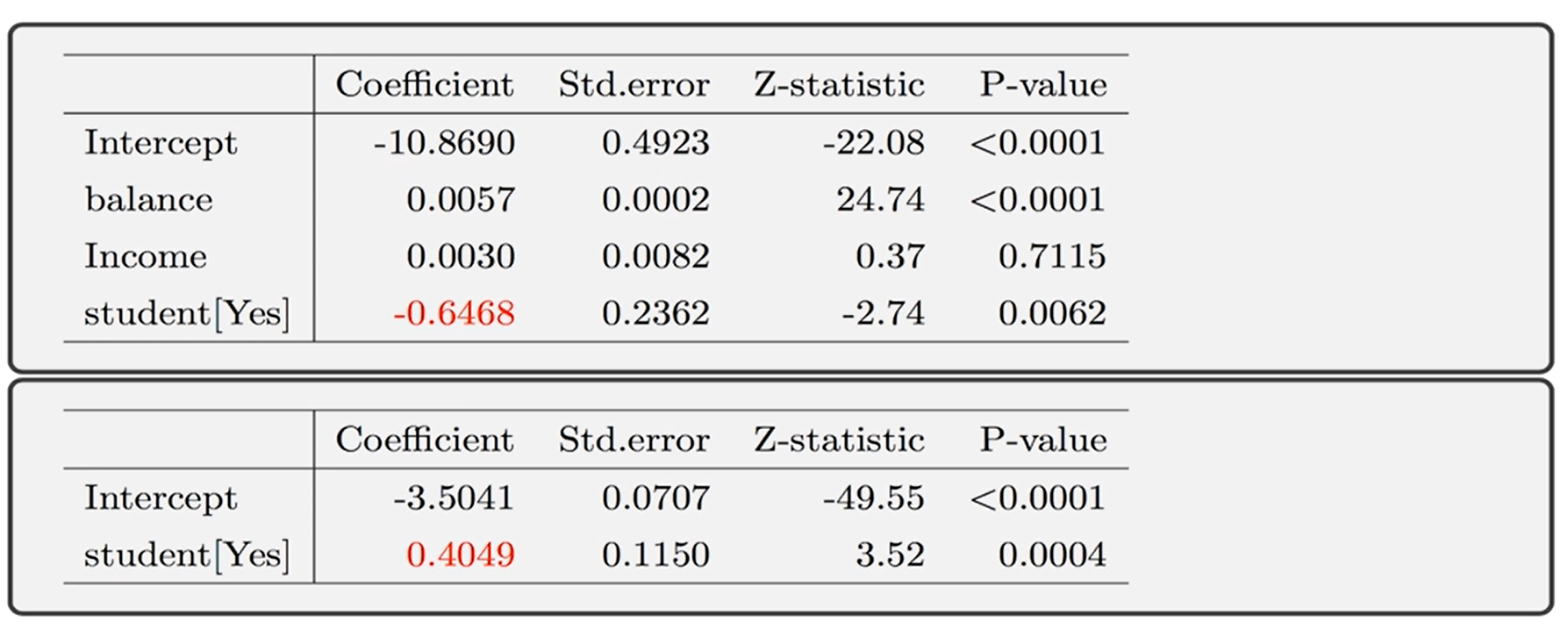
发现Student[Yes]的回归系数是0.4049,自变量放虚拟变量的方法和之前的是一模一样的,在R里只需要把这一列数据类型改为因子类型(factor)。
下面讲讲怎么解释分类型虚拟变量的回归系数,以上图为例,可以说是学生和不是学生它们对数发生比的差距是0.4049。具体来看看,如果是学生,欠账的平均概率是4.31%,如果不是学生,欠账的平均概率是2.92%。这就体现出是学生不是学生,他们欠账的概率有明显的差距,差了4.31%-2.92%.
Logistic Regression模型评价
我们刚才对Student分类型变量单独做一元Logistic回归的时候,发现回归系数数0.4049,但是进行多元Losgitic回归的时候发现,它的回归系数变成-0.6468了,变负了。怎么回事呢?
实际上,这是因为数据里面,student变量与balance(欠账额度)相关,而student通常有较高额的欠账,高额的欠账和较高的default(违约)概率相关,所以将响应变量default和分类自变量student单独分析到时候才变成了0.4049。但是,把balance控制一下,在同一欠账额度下,学生的违约风险是比较低的,所以才出现了上面的-0.6468。
所以单独看两变量的关系就做决策是很大胆的。在上面的例子中,是否为学生和欠账额度均对违约的概率有影响,但实际上影响力更大的是欠账额度。这也彰显了多元回归的重要性,一定要控制其他变量不变的情况下再来关注某一个变量对y的净影响。
R语言时间
用到的是ISLR包中的Smarket数据。使用 names() 函数可以查看变量名称,使用 dim() 函数查看数据的行数(样本量)和列数(变量的个数)。使用 pairs() 函数查看变量两两之间的散点图。使用 cor() 函数查看变量两两之间的相关系数,要求变量为数值型,把名义型变量移除了再使用该函数。
library(ISLR)
names(Smarket)
dim(Smarket)
summary(Smarket)
pairs(Smarket)
cor(Smarket[,-9])
plot(Smarket$Volume)
# Logistic Regression
lrm1 <- glm(Direction ~ Lag1 + Lag2 + Lag3 + Lag4 + Lag5 + Volume, data = Smarket, family = binomial(link = "logit"))
lrmPred1 <- predict(lrm1, type = "response") //写response的话会预测y=1的概率,这里就是预测涨的概率
lrmPred1[1:10] //输出预测的十个概率,这里预测的是Smarket的数据
contrasts(Direction) //看看R语言是怎么抽象up和down的
#预测
lrm1.pred1 <- rep("Down", 1250) //先生成1250个Down
lrm1.pred1[lrmPred1 > 0.5] <- "Up" //把预测的涨的概率大于0.5的改成Up
table(lrm1.pred1, Direction) //看看预测的和真实的情况对比注意,如果解释变量有分类型变量,则需要用 as.factor() 函数将它们转为因子类型。
# 其他多元统计方法
下面讲讲什么情况用什么分析方法,具体怎么用需要去学习一下。
多水平分析(Multilevel Analysis)
多水平分析有很多别名,如多层线性模型(Multilevel Linear Model, MLM)、分层线性模型(Hierarchical Linear Model, HLM)、随机效应模型(Random Coefficient Model)等等。其实它们都说的同一个问题,关注的都是数据具有某种分层结构的时候的处理方法。
这种方法认为数据具有某种分层结构,通常响应变量处于最低(最微观)层级,而解释变量则处于不同的水平上。如果此时再用传统线性回归,则随机误差项不再相互独立,与假设不符。
Example
关注学生的考试成绩,当考试成绩为y的时候,这个考试成绩就处于最低(最微观)层级。它是从每一个学生(个体)记录的,但是学生嵌套于班级,班级嵌套于学校,学校嵌套于学区,学区上面还有市,市上面还有省等等。那么一个班级学生的考试成绩可能因为老师或教科书不同而不同;一个学校考生的平均成绩可能与该学校学生的社会经济地位有关。如果有多个班级/学校,那么将其作为控制变量是不现实的。
路径分析(Path Analysis)
在社会科学中不一定能把问题简化成只有一个响应变量,不一定能简化成公式左边就一个响应变量公式右边有好多好多自变量。现实问题总是比想象的复杂,有时候就会面临多原因多结果的研究问题。下图可以看到,这个y2既是自变量又是因变量。这是典型的多原因多结果之间机制的研究问题。

当遇到很多个y的时候需要怎么办?这时候就需要用路径分析的方法。
因子分析(Factor Analysis)
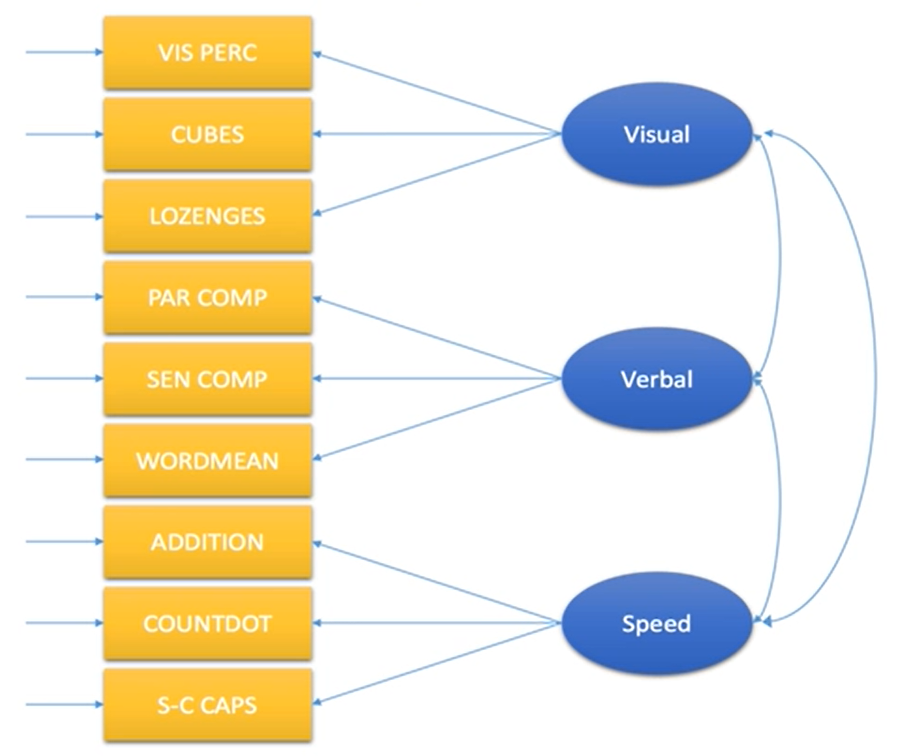
因子分析是指研究从变量群中提取共性因子的统计技术。因子分析的主要目的是用来描述隐藏在一组测量到的变量中的一些更基本的,但又无法直接测量到的隐性变量 (latent variable, latent factor)。
下图是对学生的测量,想研究一群学生他们的视觉能力、语言能力和反应能力之间有什么用的关系。但不管是视觉能力还是反应能力还是反应速度都不是特别清晰的概念,是社会学中抽象的概念,有时候叫潜变量。需要用一些媒介来测量这些潜变量。在下图中,有3个潜变量,为了对他们进行测量,每个潜变量使用3个媒介(题目)进行测量。最后找每个潜变量之间相互关系具体是什么样的。这就是因子分析的目的,因子分析经常用在量表的效度验证。
结构方程模型(Structural Equation Modeling)
结构方程模型研究潜变量的测量和建模的问题。
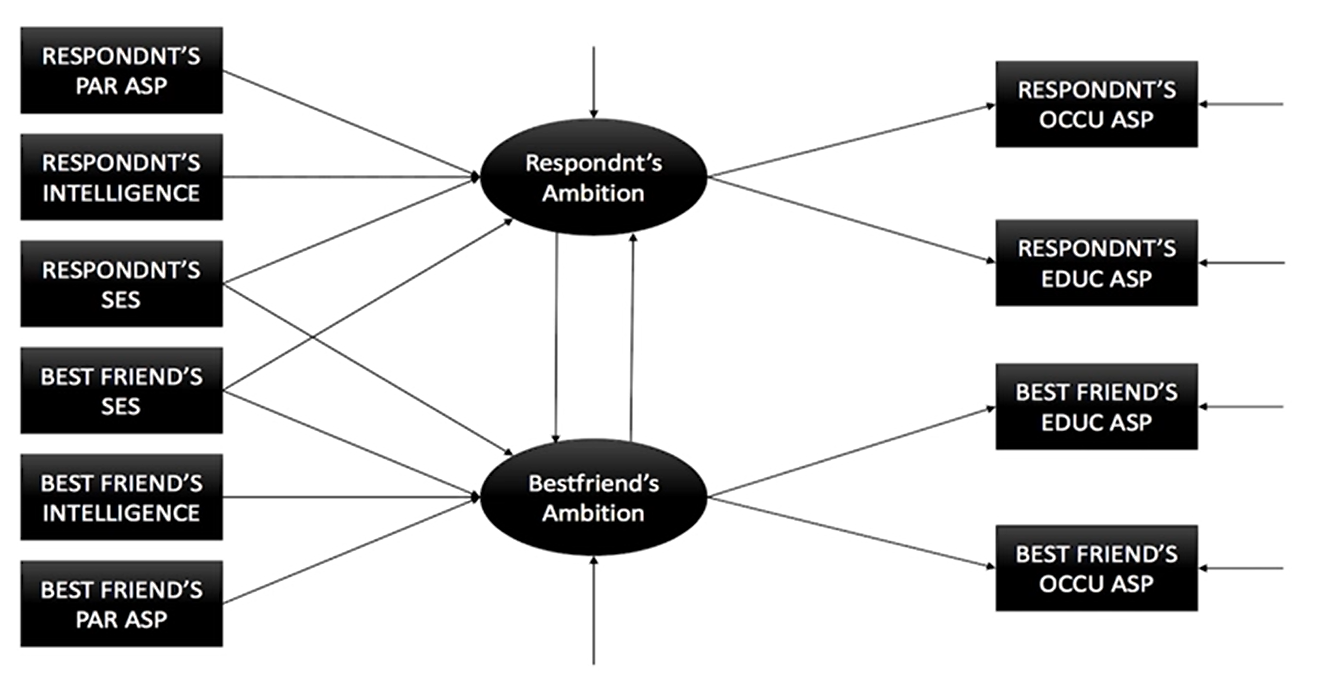
下图是非常典型的例子。以受访者为研究对象,想知道受访者的野心和他好朋友的野心之间是什么样的关系,然后搭了这个模型。模型中说受访者野心受到他父母期望、本人智商、本人社会经济地位以及最好的朋友的社会经济地位影响。野心会影响到职业抱负和教育抱负。方块表示的变量是可以直接测量的;中间圆圈的变量是人工造出来对潜变量,是不能直接测量的,需要靠职业期望和教育期望来测量。然后想办法来拟合这样一个模型看模型里面的每个箭头的大小还有模型是否成立。
此外还有计数模型、生存分析等