机器学习算法开发流程。
# 序
该帖讲述机器学习算法开发的流程与建议。
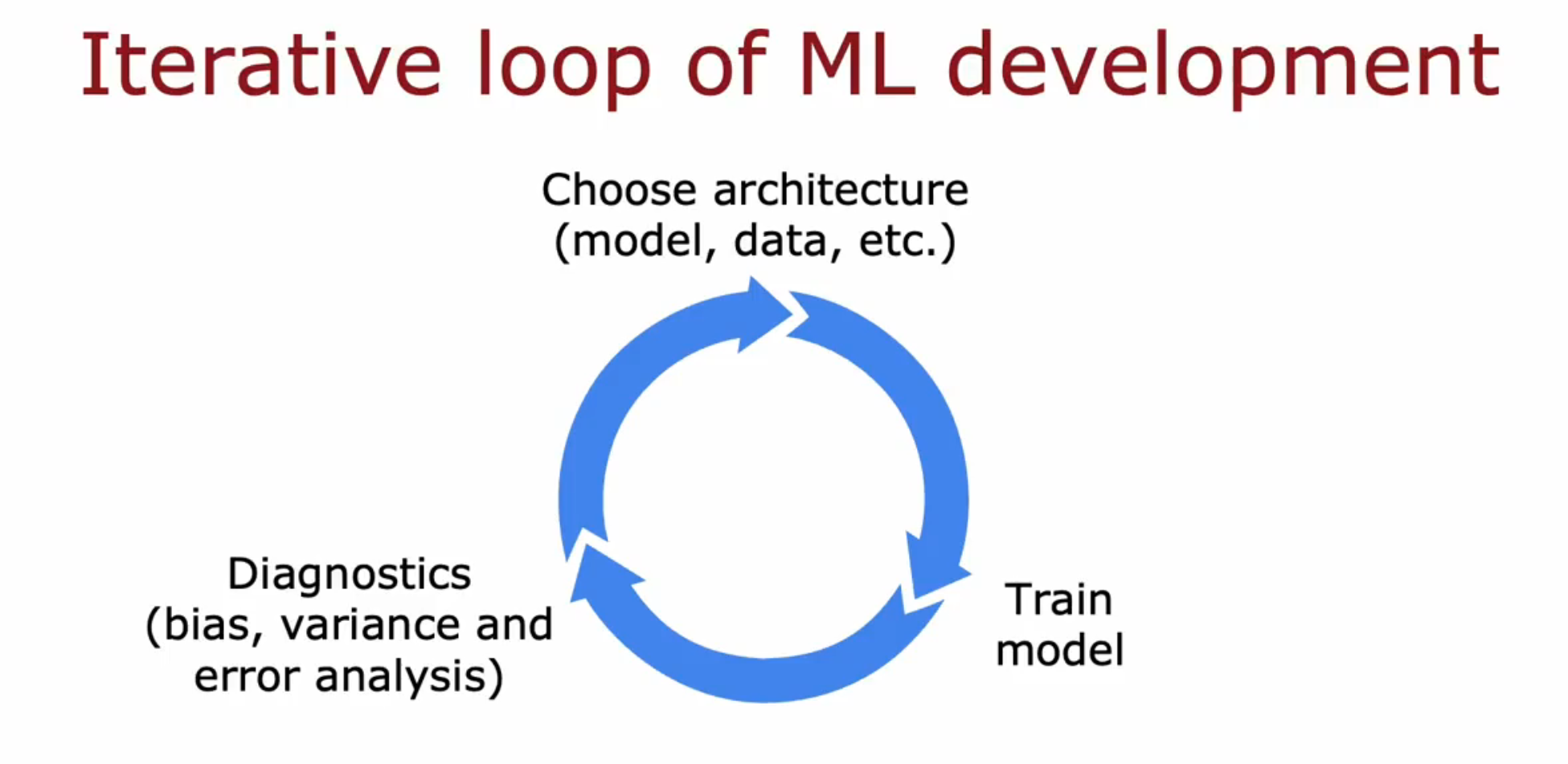
# 循环流程
首先决定系统的整体架构,如模型、数据、各种超参数等; 然后训练模型,当然结果可能并不符合预期; 然后进行诊断,如方差偏差分析(此帖)、误差分析等,并作出下一步决策; 最后回到第一步如此循环直到达到目标效果。
# 误差分析
方差偏差分析固然重要,而误差分析也是改进模型表现的重要手段。
误差分析指仅人工分析被错误分类的样本,观察并总结规律及共同特征。
以垃圾邮件分类举例,假如 mcv=500 ,而算法错误分类、未能识别其中100封垃圾邮件。仔细观察这些被错误分类、未能识别的样本发现其中21封与药品有关、3封与故意错误拼写有关、7封与不寻常路由有关、18封与钓鱼网站有关、5封与垃圾图片附件有关。
从效率来说,先花时间处理药品垃圾邮件对算法表现影响最大,其次是钓鱼网站垃圾邮件。接下来作出收集更多药品垃圾邮件与创造更多有关垃圾邮件特征的决定。
# 增加数据
除了收集数据,还有一种使数据集壮大的方法是通过已有数据人工创造新的数据。
对于不同应用的机器学习算法,人工增加数据的方法不同。在计算机视觉方面,旋转图像、缩放图像、改变图像对比度、镜像图像、网格化随机扭曲图像可能有用(根据具体应用)。
在语音识别方面,给已有数据增加各种不同的背景音可能有用。
在OCR方面,使用计算机的不同字体输入字母表并作为数据集可能有用。
# 迁移学习
如果自己的数据不够多造成模型表现欠佳,迁移学习将很好地解决这一问题。简单来说,迁移学习指将其他通过大数据预先训练好的神经网络的前几层复制到自己的神经网络中,在前人的基础上炼丹,即使别人的分类目标与自己的不同。
迁移学习分两步,第一步是其他研究人员(或自己)贡献的监督预训练 Supervised pretraining ,第二步是根据第一步得到的参数使用梯度下降等算法微调 Fine tuning 参数来适配自己的应用。
模型与数据下载链接
Hugging Face - https://huggingface.co/ # 各种模型与数据 PyTorch Hub - https://pytorch.org/hub/ # 各种适用于PyTorch的模型 GPT-3 - https://openai.com/blog/customizing-gpt-3 # NLP模型 ImageNet - https://www.image-net.org/ # 图像数据 BERT # NLP模型 Model Zoo - https://modelzoo.co/ # 各种模型
两种方式进行迁移学习的微调
1.保持前人的前几层参数不动,仅使用梯度下降等算法更新输出层的参数。
毕竟别人算法适配的应用与自己的不同,因此输出层的参数需要重新计算。如果自己的训练集很小(仅数万张),那么该方法较为推荐。
2.以前人的前几层参数为初始值,使用梯度下降等算法更新所有层的参数。
类似于站在巨人的肩膀上。如果自己拥有稍微大一点的训练集,那么推荐该方法。
迁移学习如何工作?
对于同样的任务(如图像识别),神经网络前几层的工作较为基础,即第一层识别边缘,下一层将边缘合在一起以识别角,再下一层识别曲线或基本形状。实际上前几层神经网络都在学习这些基本形状,因此可以将他人训练好用作识别动物的模型套用在识别数字中。
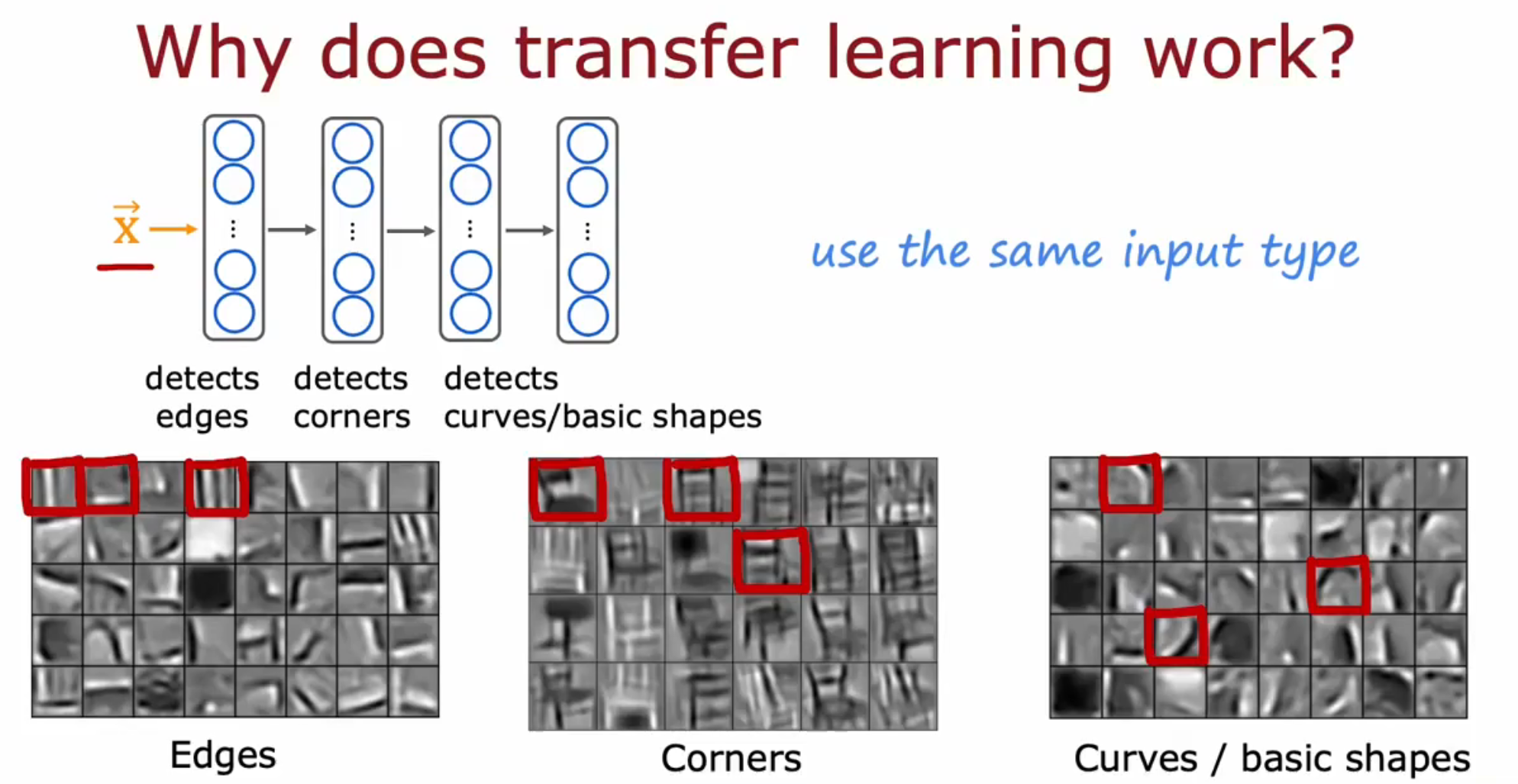
此外,用于文本识别的有监督预训练模型不能提升图像识别的效果。在迁移学习中,需要确定他人的有监督预处理模型的输入数据的维度是否与自身研究匹配。